
Supervised learning catches known cyberattacks by training a model on labeled examples of “malicious” and “benign” activity, so it can spot the same patterns when they appear again.
By learning these digital fingerprints, the system becomes very good at recognizing repeat offenders, which helps reduce noisy false positives and gives security teams clearer, more focused alerts.
This approach is especially useful when you have strong historical data and want reliable, explainable detection rather than guesswork. Keep reading to see how you can apply supervised learning to strengthen your own cybersecurity strategy in a practical, structured way.
Key Takeaways
- It relies on labeled historical data to recognize known attack patterns.
- Models like Random Forests excel at classifying malware and phishing attempts.
- Its main weakness is an inability to detect novel, unlabeled threats.
How Supervised Learning Sees Threats
You stand at the edge of a digital river, watching packets of data flow by. Most are harmless, but some carry poison. The challenge isn’t just seeing the river, it’s knowing which drops are toxic.
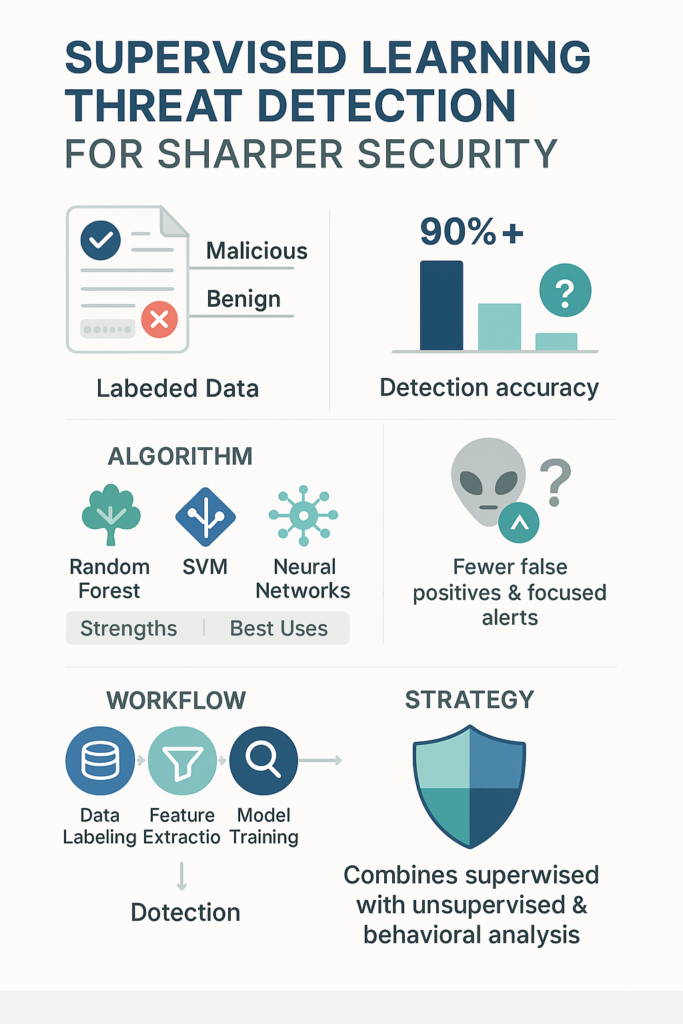
Supervised learning threat detection gives you that knowledge. It’s a method of teaching a machine to spot the bad apples by showing it thousands of examples of good and bad ones first. This isn’t about guessing. It’s about pattern recognition on a scale humans can’t match [1].
The process begins with data labeling, a painstaking but critical task. Security analysts pore over historical network traffic, system logs, and email records.
They tag each event, marking it as a specific type of attack or as normal activity. This creates the ground truth, the labeled dataset that the model will learn from. Poor labels degrade model performance significantly.
Next comes feature extraction. The raw data is too messy. The system needs to pull out meaningful signals, features. For network traffic, this might be the packet size, the source IP address, or the protocol being used.
For a file, it could be the file size, the sequence of API calls it makes, or strings of code within it. These features become the dimensions in a mathematical space where the model will operate.
Then the model trains. Algorithms like Support Vector Machines (SVM) or Random Forests ingest the labeled features. An SVM, for instance, tries to find the clearest possible boundary, a hyperplane, that separates the malicious data points from the benign ones.
A Random Forest builds a multitude of decision trees, each asking a series of simple questions about the features, and then combines their votes for a final, robust classification.
The Algorithms on Your Side
| Algorithm | Strengths | Best Used For | Limitations |
| Random Forest | Handles complex relationships, robust to noise | Malware classification, phishing detection | Can be heavy with very large datasets |
| SVM | Clear separation of malicious vs benign data | Binary threat classification, intrusion detection | Slower on very large datasets |
| Neural Networks | Learns non-linear, complex patterns | Email phishing detection, behavior modeling | Requires large labeled datasets, risk of overfitting |
Several algorithms have proven particularly effective in the cybersecurity domain. They each have their own strengths, like different tools in a detective’s kit.
- Random Forests: Often a top performer, they combine many decision trees to avoid overfitting and handle complex feature relationships well.
- Support Vector Machines (SVM): Excellent at finding clear separation boundaries in high-dimensional data, great for binary classification tasks.
- These algorithms are foundational in applying machine learning cybersecurity strategies that transform how threats are detected and prioritized, making your security posture more proactive and data-driven.
- Neural Networks: Especially deep learning models, can model highly complex, non-linear patterns, like those found in sophisticated phishing emails.
The training phase is iterative. The model makes predictions on the training data, and an algorithm adjusts its internal parameters to reduce errors.
This continues until the model’s accuracy on a held-out validation dataset is satisfactory. It’s a process of tuning and refinement, ensuring the model generalizes well to new, unseen data that resembles its training set.
Where It Shines in Practice
This approach isn’t theoretical. It’s actively defending networks right now. Its precision with known threats makes it invaluable for specific, high-volume tasks.
One major application is phishing detection. Models are trained on hundreds of thousands of emails labeled as “phishing” or “safe.” They learn to spot subtle cues in the email headers, body text, and embedded links that humans might miss.
This allows for the automatic filtering of a huge percentage of phishing attempts before they ever reach an inbox.
Supervised learning models, especially those refined with insights from deep learning for network security, enhance the accuracy of phishing detection by leveraging complex patterns beyond simple rules.
Another critical use is malware classification. By analyzing features of executable files, such as their binary sequences, file entropy, and system calls, a supervised model can quickly determine if a file is malicious.
This powers next-generation antivirus solutions that go beyond simple signature matching. It’s also the backbone of network intrusion detection systems (IDS).
These systems analyze live network traffic, comparing it to patterns of known attacks like DDoS attempts or port scans, and raising alerts in real-time.
The strength here is clarity. For these known threats, supervised models can achieve remarkably high accuracy, frequently exceeding 90% on well-curated datasets.
This directly translates to a reduction in alert fatigue for Security Operations Center (SOC) analysts. Fewer false positives mean analysts can focus their energy on genuine incidents.
The Inevitable Blind Spots
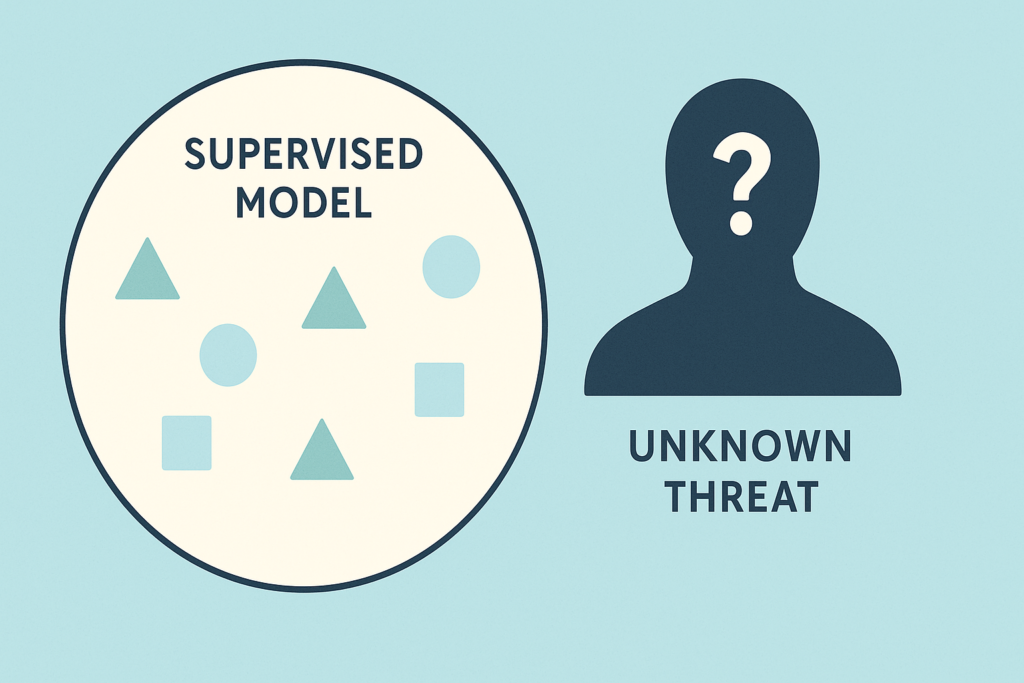
For all its power, supervised learning threat detection has a fundamental limitation. It can only find what it has already seen.
A model trained to recognize a thousand types of malware will be blind to the thousand-and-first, novel zero-day attacks. It lacks the inherent curiosity to spot something truly novel. This is its Achilles’ heel [2].
The dependency on labeled data creates other problems. Obtaining high-quality, comprehensively labeled datasets is difficult and expensive.
The data must also be representative of the real world. If a training dataset lacks examples of a certain attack vector, the model will be weak against it. Worse, biases in the data can lead to biased models, which might overlook threats targeting specific systems or networks.
Adversaries also adapt. They study these detection systems and develop techniques to evade them. This is known as adversarial machine learning.
An attacker might subtly manipulate the features of a malicious file just enough to trick the model into classifying it as safe, all while maintaining its malicious function. This necessitates a constant cycle of retraining the models with new examples of evasive attacks.
This leads to the operational overhead. These models aren’t fire-and-forget weapons. They degrade over time as the threat landscape evolves.
They require a continuous pipeline of fresh, labeled data and periodic retraining to maintain their effectiveness. This demands significant resources and expertise.
A Strategy for Supervised Detection
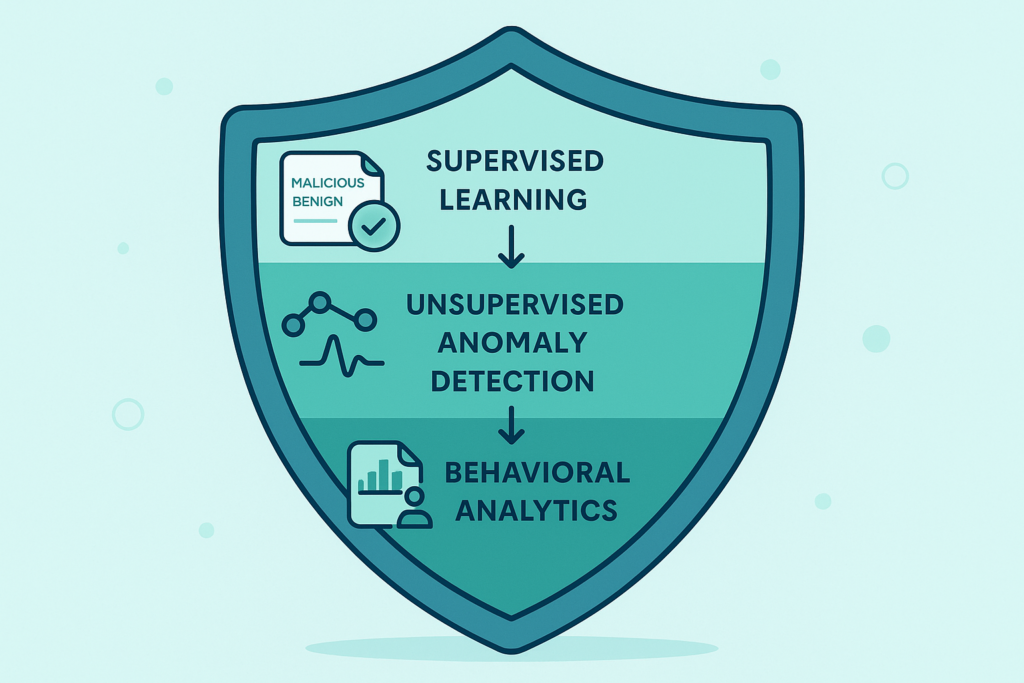
So, where does this leave you? Supervised learning threat detection is a powerful component of a modern security stack, but it cannot be the only component.
Its ideal role is as a precision scalpel, not a blunt shield. Use it for what it does best: automating the detection of known, high-volume threats.
Deploy it to handle phishing emails, classify known malware, and flag common network intrusions. This frees up your human analysts.
Integrating machine learning & ai in ntd can further optimize these processes, enabling continuous model improvement and adaptive detection capabilities that keep pace with evolving cyber threats.
But you must complement it with other approaches. Unsupervised learning methods, which look for statistical anomalies without prior labels, can help spot novel attacks.
Behavioral analysis that establishes a baseline of normal activity for a user or system can flag deviations that might indicate a breach. The most resilient security posture layers these different techniques together.
The goal is a balanced defense. Let supervised learning handle the known wolves at the door. Use other methods to listen for unexpected noises in the woods.
This combination provides both precision and a capacity for surprise, which is essential in a fight where the opponent is always innovating. Start by applying supervised models to your clearest, noisiest problems and build out from there.
FAQ
How can supervised threat detection help me handle cyber risks in a clearer and faster way?
Supervised threat detection uses labeled data cybersecurity methods to learn known attack patterns. It supports security event classification and supervised anomaly scoring to separate real threats from harmless activity.
When you use supervised detection pipelines and supervised SIEM analytics, the system gives you cleaner alerts with fewer mistakes. This helps you respond faster and stay focused on real risks.
What data do I need to start using supervised intrusion detection in my environment?
You need labeled threat datasets, network traffic labeling, cyber event labeling, and labeled intrusion datasets.
These datasets support intrusion detection classification and threat vector classification. When the data is clear and consistent, classifier-based IDS tools can learn patterns well.
This improves supervised threat detection models, strengthens ML detection accuracy optimization, and lowers the number of wrong alerts.
How do machine learning threat models reduce false alerts in daily SOC work?
Machine learning threat models use false positive reduction ML, supervised SOC automation, and supervised alert prioritization to rank events more accurately.
They learn from attack pattern classification and supervised behavioral threat modeling. With help from supervised model tuning and ML-based threat scoring, the system sends fewer noisy alerts. This allows SOC teams to focus on real threats and respond more quickly.
What models work best if I want stronger malware and phishing protection?
You can use malware classification algorithms, classifier-based malware analysis, supervised malware detection, phishing detection ML, and supervised phishing email classification.
Models such as SVM threat detection, random forest cyber classification, and neural network threat classifier support supervised cyber analytics. They learn from labeled log dataset training and supervised exploit detection to catch harmful files and phishing attempts early.
How can I improve accuracy when building supervised threat detection models?
You can improve accuracy by using feature engineering for threats, supervised model validation security, and supervised algorithm benchmarking.
You can also apply supervised deep learning IDS, supervised network packet analysis, time-series threat classification, and supervised endpoint anomaly detection.
Clean data and supervised behavior modeling support stronger supervised cybersecurity predictions. Good tuning and ML-based detection workflows produce clearer and more reliable alerts.
Building Precision Defense with Supervised Learning
Supervised learning threat detection delivers high-precision defense by recognizing known attack patterns with remarkable accuracy, easing the burden on analysts and strengthening day-to-day security operations.
But its dependence on labeled data and its blindness to novel threats make it only one piece of a resilient strategy.
Pairing it with unsupervised models, behavioral analytics, and continuous retraining creates a layered, adaptive security posture, one that catches what you expect and stays alert for the threats you’ve never seen. Ready to sharpen your threat detection strategy? Join the next step here.
References
- https://besjournals.onlinelibrary.wiley.com/doi/10.1111/2041-210X.13992
- https://arxiv.org/html/2512.07030v1
