
Centralizing cloud logs SIEM means bringing logs from AWS, Azure, and GCP into one place for clearer threat detection and faster investigation. Most teams now run multi-cloud setups, so scattered logs are a real challenge. We’ve seen this firsthand in our threat modeling work, gaps across identity, network, and workload data often slow response times.
A centralized setup helps, but only when it’s done with the right structure and priorities. Otherwise, it can create more noise than value. In this guide, we’ll share what has actually worked in real environments. Keep reading to see how to do it right.
Centralizing Cloud Logs SIEM: What Matters Most
If you get the basics right, centralizing cloud logs SIEM improves detection without adding cost or noise.
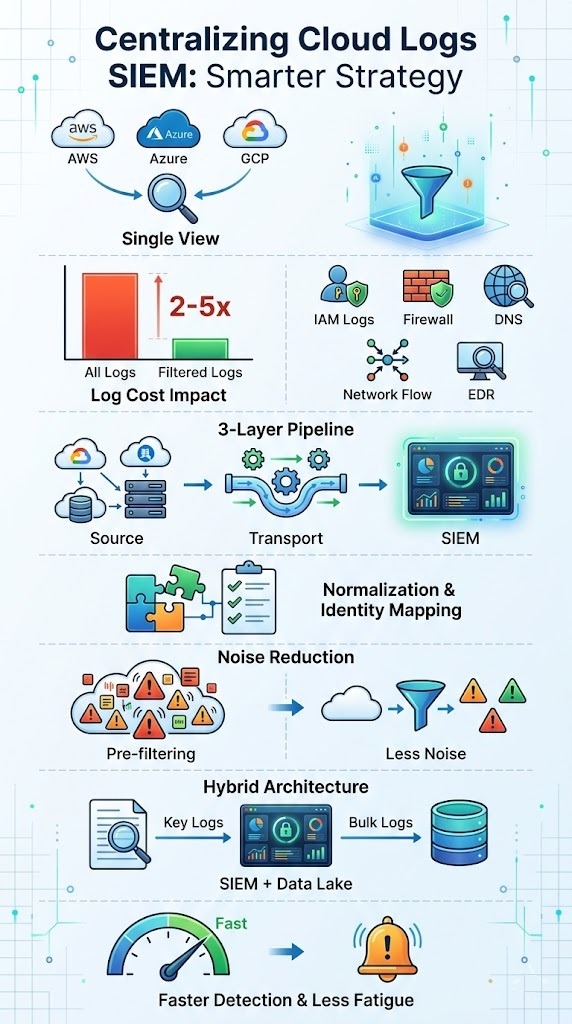
- Centralized logging speeds up detection by letting you correlate events across clouds and giving your SOC one clear view.
- Sending every log creates noise and can increase costs 2 to 5 times without improving detection.
- Strong results depend on normalization, selective ingestion, and a well-designed pipeline.
What Does Centralizing Cloud Logs in a SIEM Actually Mean?
It means collecting logs from cloud platforms into one system. You give them consistent formats, timestamps, and extra context so you can detect threats and investigate incidents. Cloud services like AWS CloudTrail, Azure Activity Logs, and Google Audit Logs all produce logs differently. Without fixing that, your data is just fragmented.
A centralized system aligns these logs into a shared structure using a normalization schema. This lets you correlate events across identity, network, and workload activity. CrowdStrike says structured log aggregation can boost detection efficiency by over 30%.
In our work, we start with Network Threat Detection as the first layer. We focus on network flow logs, DNS logs, and firewall logs before adding more. That initial visibility often shows lateral movement faster than looking at identity logs alone.
The main parts of centralization are:
- Aggregating logs across AWS, Azure, and GCP.
- Using SIEM data connectors to bring them in.
- Enriching logs with context like user roles and asset tags.
- Doing cross-cloud correlation using normalized fields.
This turns raw logs into useful signals, not just a searchable archive.
Why “Send All Logs to SIEM” Is a Myth in Practice

At first glance, sending every log into a SIEM sounds like the safest move. More data should mean better visibility, right? In practice, it rarely works that way. We’ve seen teams fall into a “log-spray-and-pray” approach, where everything gets pushed in without much thought. The result is noise, not clarity.
From what we’ve observed in real environments, high-volume sources like container logs and serverless functions quickly flood pipelines. Most of that data doesn’t help with actual threat detection. It just slows everything down. Research backs this up too, studies suggest a large portion of logs bring little security value once inside a SIEM.
In our own work building threat models and risk analysis, we’ve learned that more data isn’t the goal, better data is. When teams ingest everything, a few common issues show up:
- Costs rise fast due to heavy ingestion and storage
- Alerts become noisy, leading to missed real threats
- Analysts spend too much time tuning instead of investigating
A more focused approach works better. When logs are filtered with intent, detection improves, and teams can actually act on what they see.
What Logs Should You Actually Centralize?
Credits: SystemDR – Scalable System Design
Not all logs deserve a spot in your SIEM. The ones that matter most are tied to identity, access, and network activity. These are the logs that help answer a simple question during an incident: who did what, when, and from where.
In many environments we’ve worked with, security teams start by focusing on identity and access logs, along with network-level data. That’s where real signals tend to show up. From our side, using Network Threat Detection early gives us fast visibility into suspicious traffic patterns. It helps us see risks forming before they turn into incidents.
Over time, we’ve found that a small set of logs delivers most of the value. Teams usually get the best results by prioritizing:
- IAM logs, especially anything tied to privileged users
- Firewall logs, DNS logs, and network flow logs
- Endpoint telemetry and EDR data
- Storage access logs like S3 or cloud storage
There’s a clear pattern here. A small portion of log sources drives most detections. Once pipelines are stable and tuned, then it makes sense to expand, but not before.
How Does Three-Layer Architecture Work?
Most centralized cloud logging setups follow a simple three-layer model. It starts with the source systems, then moves through a transport pipeline, and ends in the SIEM. Cloud platforms like AWS, Azure, and Google Cloud act as the source. They generate raw logs across services, regions, and workloads.
Once logs are created, they don’t go straight to the SIEM. They pass through a transport layer first. In many setups we’ve worked on, this includes streaming tools, queues, or API-based pipelines that move data reliably. A strong cloud environment log collection setup at this stage helps reduce data loss and keeps ingestion consistent across sources
At the end of the flow sits the SIEM. This is where logs are parsed, indexed, and analyzed for threats. The full path usually looks like this:
- Source: Cloud services, apps, and infrastructure
- Transport: Pipelines, queues, or streaming tools
- SIEM: Detection, correlation, and dashboards
What often gets overlooked is pipeline design. We’ve seen issues not at ingestion, but during transformation. If log formats aren’t consistent, correlation breaks. That’s why early normalization decisions matter more than most teams expect.
What Are the Common Architectures for Centralization?
There isn’t one single way to centralize logs. Each setup trades off cost, scale, and detection depth. What works best usually depends on how mature the team is and how much data they handle daily.
In practice, most organizations fall into a few common patterns:
| Architecture | Description | Use Case |
| Cloud-native SIEM | Direct ingestion using built-in connectors | Fast deployment |
| Data lake SIEM | Logs stored in scalable storage, queried later | Cost optimization |
| Hybrid model | SIEM for key logs, storage for bulk data | Balanced approach |
Early on, teams often choose cloud-native SIEM because it’s simple to set up. Over time, though, costs grow as more logs are added. That’s when data lake or hybrid models start to make more sense.
From what we’ve seen in real deployments, hybrid setups tend to work best. We use them alongside our threat models and risk analysis to keep detection sharp without overspending. Critical logs stay in the SIEM for fast response, while lower-value data moves to cheaper storage.
This balance helps teams scale without losing visibility, especially in complex or multi-cloud environments.
Why Normalization and Identity Mapping Are Non-Negotiable
At some point, every team runs into this problem, logs don’t line up. Without normalization and identity mapping, cross-cloud detection starts to break down. You can’t reliably connect events, even if the data is there.
Different platforms speak different “languages.” One system might use resource IDs, while another uses email addresses for the same user.
From our experience building threat models and risk analysis workflows, fixing this early makes a big difference. When normalization is weak, detection becomes noisy and harder to trust. Teams often deal with more false alerts and missed signals.
To get this right, a few things matter most:
- Standard log formats across all data sources
- Identity mapping to tie actions to real users
- Consistent timestamps and event categories
Over time, we learned that parsing and transformation aren’t optional steps. We treat them as core parts of the pipeline. Without that foundation, correlation rules may look good on paper, but they won’t hold up in real-world detection.
How Do You Handle Multi-Tenant and Client Isolation?
Multi-tenant logging needs strict separation of data. You use logical or physical isolation mechanisms. Managed service providers often struggle when centralizing logs across different clients.
Bad design leads to data getting mixed up and compliance risks. This becomes more visible when working with google cloud platform gcp logging, where audit logs and identity data often follow different structures than other cloud providers.
Data from the SANS Institute demonstrates
“Data isolation in multi-tenant environments traditionally relies on virtualization and privilege separation… A principled framework must map tenancy policies to concrete hardware and software primitives, enforcing those policies at runtime with verifiable guarantees to balance security with the practical need for multiplexing resources.” – SANS Institute
Solutions usually include:
- Dedicated indexes or separate environments for each client.
- Strong SIEM RBAC and access segmentation.
- Tagging strategies for client-specific logging.
Industry studies show misconfigured access controls affect over 60% of SIEM deployments. In our work, designing isolation early avoids a painful re-architecture later. This is especially important when scaling multi-tenant logging environments.
What Are the Biggest Operational Challenges for SOC Teams?
SOC teams deal with cost, complexity, and alert fatigue when managing centralized cloud logs. Maintaining parsers is a continuous job because cloud providers keep updating their log formats. Teams often underestimate this workload.
At the same time, poorly tuned SIEM correlation rules create too many alerts. This becomes even harder when dealing with the challenges monitoring multi cloud environments, where data comes from different systems with different formats and levels of detail.
In a recent analysis by Chitrakshi (Security Integration Lead) via Medium / Modern Security Stacks
“As new systems are onboarded, log ingestion volumes grow rapidly… Yet detection precision does not improve automatically. Normalization inconsistencies distort correlation. Duplicate logs inflate noise. Detection rules fire repeatedly because contextual fields are missing. False positives accumulate. The operational strain is tangible.” – Modern Security Stacks
According to In-Sec-M, analysts spend more than 50% of their time managing alert noise. Common operational challenges are:
- Keeping custom parsers and schemas up to date.
- Managing alert fatigue and false positives.
- Scaling ingestion for high-volume logs.
This is where starting with Network Threat Detection helps. By focusing on network-level signals, we reduce noise before it ever reaches the SIEM layer.
How to Optimize Cost and Performance in SIEM Logging
Keeping SIEM costs under control isn’t about cutting corners, it’s about being selective. The teams that do this well focus on what they ingest, how they store it, and where it lives over time.
In most environments we’ve worked in, a tiered approach makes the biggest difference. Critical logs go straight into the SIEM for real-time detection, while bulk data is stored in cheaper options like object storage. This keeps performance steady without driving up costs.
From our experience building threat models and analyzing risk, sending everything to the SIEM rarely pays off. It slows queries and adds noise. A more focused pipeline helps both detection and response stay sharp.
There are a few practical steps teams rely on:
- Filter logs before they reach the SIEM
- Use compression and encryption during transport
- Move older or less critical logs into cold storage
What stands out over time is this, optimization isn’t a one-time fix. We’ve had to adjust pipelines as data grows and threats change. The balance between cost and performance needs regular tuning to stay effective.
Why “One Pane of Glass” Often Fails in Reality
The idea of a “one pane of glass” sounds great, but it rarely works as expected. Even with centralized logging, many teams still jump between tools. We’ve seen this happen in real environments where everything looks connected on paper, but not in practice.
A big reason is how the data is handled behind the scenes. Logs may be centralized, but they aren’t always consistent or easy to use. From what we’ve experienced, poor normalization and scattered pipelines make it hard to trust what you see in one place.
In our work with threat models and risk analysis, we often find that visibility isn’t the real problem, usability is. Teams can see data, but they struggle to act on it.
Some common issues show up again and again:
- Inconsistent schemas that break queries
- Missing identity mapping, making correlation weak
- Dashboards that lack clear, actionable context
Over time, this leads to a bigger issue. Instead of helping with detection, the SIEM turns into a storage system for logs. We’ve seen teams rely on other tools just to fill the gaps, which defeats the purpose of having everything in one place.
When a Centralized SIEM Is the Wrong Approach
At a certain scale, a fully centralized SIEM can start to work against you. As data grows across cloud environments, costs rise, queries slow down, and systems get harder to manage. We’ve seen cases where log volume alone pushes indexing past its limits.
In real-world setups, this often leads to delays or even dropped events. That’s a serious risk. When data doesn’t arrive on time, detection suffers. From our experience working with threat models and risk analysis, this is where teams need to rethink their approach.
Many organizations are now shifting toward a more flexible model. Instead of forcing everything into one system, they split responsibilities across layers. A common pattern looks like this:
- SIEM handles high-value logs for real-time detection
- Data lakes store large volumes of raw or historical logs
- Correlation is applied selectively, based on risk
We’ve found this approach works better in modern cloud environments. It reduces pressure on the SIEM while keeping detection focused. Over time, it also makes systems easier to scale without losing visibility where it matters most.
FAQ
How does centralized logging improve SIEM integration in multi-cloud environments?
Centralized logging brings data from different cloud platforms into one place, which makes SIEM integration easier to manage. It supports better cloud log aggregation, so teams can view activity across systems without switching tools.
This setup improves SOC visibility and helps teams detect threats and respond to incidents faster. It also reduces gaps that often appear in multi-cloud logging environments.
What logs are most important for threat detection and event correlation?
The most important logs include identity and access logs, network flow logs, and system activity logs. These include IAM logs, VPC Flow Logs, DNS logs, firewall logs, and WAF logs. These logs help security teams track user actions and system behavior. Focusing on these sources improves event correlation and reduces false positives from high-volume logs.
How does log normalization support better SIEM correlation rules?
Log normalization ensures that data follows a consistent format across all sources. This makes SIEM correlation rules more accurate and easier to maintain. With clear log schemas and proper parsing, teams can connect events across systems.
It also supports entity resolution and user-based correlation, which improve detection accuracy and reduce missed threats.
What role does a log ingestion pipeline play in SIEM performance?
A log ingestion pipeline manages how data moves into the SIEM system. It includes log forwarding, transport, and filtering steps.
When designed properly, it improves SIEM performance and reduces delays in processing. It also helps manage high-volume logs, supports log compression, and prevents system overload that can slow down searches and alerts.
How can teams reduce SIEM cost while keeping strong detection?
Teams can reduce SIEM cost by using log filtering and log-tiering strategies. High-value logs are stored in hot storage, while less critical data is moved to cold storage for logs. This approach supports SIEM cost optimization without losing visibility. It also improves system performance and helps manage SIEM licensing and long-term log retention.
Make SIEM Log Centralization Actually Work
You’re pulling in logs from everywhere, but the signal gets buried fast and your SIEM feels harder to trust. It slows investigations and makes important alerts easier to miss. That’s the problem.
Focus on bringing in the right data and keeping it clean from the start. Network Threat Detection helps surface useful signals early so your pipeline stays clear and reliable. Build step by step, aligned with how your team actually works. Ready to improve detection? Join Network Threat Detection
References
- https://www.sans.org/blog/airsnitch-wi-fi-client-isolation-what-security-teams-actually-need-know
- https://medium.com/@chitrakshi144/siem-integration-challenges-in-modern-security-stacks-cfca848db213
