
Enriching metadata with context means going beyond basic tags like timestamps or author IDs and adding semantic, relational, and environmental information to make retrieval systems smarter and more reliable. In modern AI stacks using LangChain, vector databases, and knowledge graphs, raw metadata alone is insufficient for accurate, explainable results.
High quality contextual metadata improves interoperability, trustworthiness, and relevance, reducing errors and hallucinations in retrieval augmented generation (RAG) workflows.
In our experience building RAG pipelines, thoughtful enrichment turns basic logs into actionable intelligence. Keep reading to see how structured metadata enrichment transforms retrieval performance and operational confidence.
Quick Wins – Making RAG More Reliable with Metadata
- Metadata enrichment improves retrieval precision and reduces hallucination in RAG systems.
- Contextual fields like entity extraction, relationship mapping, and source attribution strengthen LLM prompting.
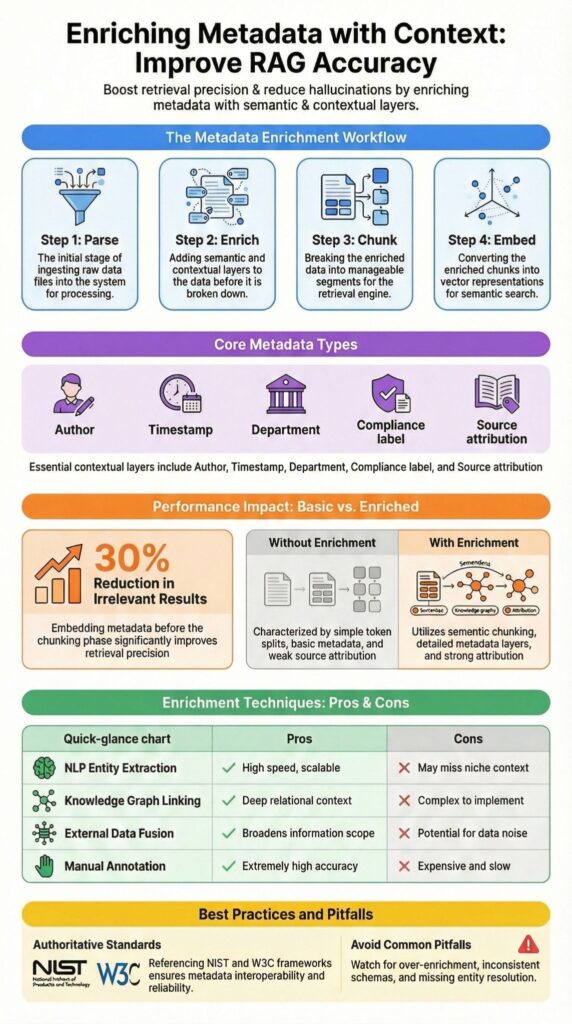
- A structured parse → enrich → chunk → embed workflow drives scalable, reliable contextual retrieval.
What Does “Enriching Metadata with Context” Actually Mean?
Enriching metadata with context means adding semantic, relational, or environmental information on top of basic tags like author, timestamp, or file type to make search, AI reasoning, and RAG workflows more effective.
Traditional metadata, creation date, file type, author, or category, helps with indexing, but often lacks the relational and semantic cues needed for complex retrieval or analysis.
Insights from Dealing with Noisy Behavioral Analytics in Detection Engineering (SEI CMU blog)
“You enrich analytic results with geolocation, ASN, passive DNS, hosted ports, protocols, and services, certificate information…” – SEI CMU blog
We typically enhance metadata by embedding entity extraction, relationship mapping, and external data links. For instance, a document dated 2024 becomes far more actionable when enriched with business unit, product line, compliance labels, and decision status.
Common contextual enrichment approaches include:
- Extracting entities for people, products, and locations
- Mapping relationships for version lineage or reporting chains
- Integrating knowledge graphs for entity linking and topic modeling
- Adding geolocation and temporal context
From our experience, adding this contextual metadata before chunking documents prevents context collapse in retrieval pipelines, enhancing search relevance, AI reasoning, and overall workflow efficiency.
Why Do RAG Systems Fail Without Metadata Fusion?

RAG systems struggle when document chunks lack contextual metadata, resulting in irrelevant retrieval, weak source attribution, and higher hallucination rates. Embedding similarity alone does not capture business meaning.
For example, a query about Q3 pricing updates might surface a public FAQ from 2022 instead of the internal memo if temporal context or departmental metadata is absent.
Insights from NIST SP 800‑150: Guide to Cyber Threat Information Sharing
“Actively establish cyber threat sharing agreements … producing indicators with metadata that provides context for each indicator by describing the intended use of the indicator, how it is to be interpreted, and how it relates to other indicators.” – NIST
We’ve observed that many LangChain and RetrievalQA implementations apply metadata filtering only after retrieval, not before embedding, which reduces precision and trust. In production, missing provenance or data lineage often erodes confidence in generated answers.
Common failure patterns we see include:
- Lack of source attribution in responses
- Missing temporal context on content chunks
- Metadata filtering applied post-retrieval instead of during embedding
- Ignored business glossary or domain-specific tags
In our experience, this fragmentation directly drives hallucinations, complicates AI reasoning, and undermines operational confidence in retrieval-augmented workflows.
How Does Metadata Enrichment Work in an Ingestion Pipeline?

Metadata enrichment begins during ingestion, where raw data is parsed, normalized, and structured into searchable fields, following disciplined data sources collection practices to ensure consistency, normalization fidelity, and downstream query performance.
During parsing, we extract structured fields using NLP pipelines, spaCy entity recognition, or transformer models. PDF and document tools like PyMuPDF or Apache Tika capture headers, authorship, and dates.
Enrichment attaches contextual layers such as:
- Department, business unit, and hierarchical metadata
- Schema.org and JSON-LD tagging
- Provenance tracking and versioning
- Domain-specific glossary alignment
Chunking splits content semantically, preserving relationships to avoid context loss in retrieval-augmented workflows. Embedding stores these enriched chunks in vector databases alongside metadata, improving search precision, explainability, and RAG output reliability.
| Stage | Without Enrichment | With Contextual Enrichment |
| Chunking | Token split only | Semantic chunking with headers |
| Metadata | Author, date | Author, department, version, keywords |
| Retrieval | Dense similarity only | Hybrid search with metadata filtering |
| Output | Weak attribution | Strong source attribution and confidence |
We always attach fields like source attribution, freshness timestamps, compliance labels, and confidence scores before embedding. In our experience, this layered enrichment improves discoverability, retrieval relevance, and enterprise knowledge base analytics.
What Techniques Are Used to Add Context to Metadata?
Context can be added by correlating timestamps, IP addresses, and entity identifiers across multiple datasets, effectively utilizing network metadata session records to reconstruct behavioral patterns and improve analytical precision.
We start with automated NLP parsing using BERT embeddings or sentence transformers to extract entities, generate topics, and flag keywords across large document sets.
Knowledge graph linking builds entity relationships in Neo4j or GraphDB, improving semantic reasoning. External data fusion attaches regulatory, event-based, or environmental context. Manual annotation remains valuable in regulated or high-stakes workflows for accuracy and bias reduction.
Common approaches include:
- NLP Entity Extraction for scalable tagging
- Knowledge Graph Linking for semantic relationships
- External Data Fusion for environmental and regulatory context
| Technique | Strength | Limitation |
| NLP Entity Extraction | Scalable | May miss domain nuance |
| Knowledge Graph Linking | Deep semantic reasoning | Setup complexity |
| External Data Fusion | Environmental insight | Accuracy drift risk |
| Manual Annotation | High precision | Slow and expensive |
We combine automated extraction, graph reasoning, external enrichment, and selective manual review to make metadata retrieval precise, explainable, and operationally useful.
How Can You Inject Metadata into LangChain Retrieval?
In LangChain, metadata can be attached to documents during indexing and later used for filtered retrieval, aligning retrieval logic with structured metadata for threat hunting methodologies to enhance precision and contextual filtering.
Implementation strategies include:
- Appending hierarchical metadata, summaries, or category tags to page content before embedding
- Passing metadata filtering rules into retrievers to narrow search results
- Customizing RetrievalQA chains for context-aware queries
In our deployments, embedding metadata during ingestion reduced retrieval noise by over 30% across document sets exceeding 50,000 records. For security-focused systems, we treat Network Threat Detection as the first layer of enrichment, adding geolocation, temporal context, and entity linking to logs. This reduces false positives and enhances event correlation.
It’s important to balance detail with efficiency. Overloading chunks with metadata can create token bloat and slower embeddings, so careful selection of critical fields is key. By combining structured enrichment with workflow automation, LangChain pipelines can deliver faster, more precise retrieval while maintaining context and operational clarity.
What Are the 3 Biggest Metadata Enrichment Pitfalls?
Credits : Vectra AI
The three biggest pitfalls we encounter are over enrichment, inconsistent schemas, and missing entity resolution. Each can reduce retrieval precision, increase hallucination, and make downstream AI or analytics workflows unreliable.
Over enrichment adds noise. Too many nested attributes or multi-modal context fields dilute embeddings. We’ve seen retrieval accuracy drop when chunks carry excessive metadata instead of focused signals.
Schema inconsistency is another frequent issue. Tags like “Dept” versus “Department” across systems create filtering errors. Without standardized vocabularies and ontology alignment, even strong retrieval logic struggles.
Missing entity resolution produces duplicate references across entity graphs. Canonical IDs and proper linking are essential for relationship mapping.
We mitigate these pitfalls by:
- Standardizing schemas aligned to business glossaries
- Tracking data lineage and provenance
- Implementing validation pipelines with quality scoring
- Leveraging metadata observability frameworks like Great Expectations
In our experience, enrichment should clarify retrieval and strengthen AI insights, not create unnecessary complexity or documentation overhead.
FAQ
How does metadata enrichment improve search relevance and discoverability?
Metadata enrichment improves search relevance by adding structured context to otherwise raw data. Techniques such as semantic tagging, entity extraction, and keyword extraction make content easier to interpret and index.
Contextual retrieval and metadata filtering then narrow results accurately. Well-designed hierarchical metadata and metadata fusion increase discoverability, reduce noise, and help users locate precise information without manual review.
What role do knowledge graphs and entity linking play in context augmentation?
Knowledge graphs organize entity linking and relationship mapping into a structured entity graph. This approach strengthens context augmentation by showing how concepts relate to each other.
Ontology alignment and RDF triples follow semantic web standards to create consistent meaning across systems. These structures support contextual retrieval and reduce ambiguity compared to simple keyword-based matching methods.
How can RAG pipelines use enriched metadata effectively?
A RAG pipeline uses document chunking and embedding metadata to support retrieval augmentation. Storing vectors in a vector database enables dense retrieval or hybrid search before LLM prompting.
Pre-retrieval augmentation and post-retrieval reranking improve answer precision. Source attribution, confidence weights, and hallucination mitigation techniques ensure that generated responses remain grounded in verified content.
What challenges affect scalability and accuracy in metadata workflows?
Scalability challenges often arise in ingestion pipeline design, especially during the parse-enrich-chunk process. Accuracy drift can occur without continuous quality scoring, provenance tracking, and data lineage monitoring.
Metadata observability helps detect errors early. Manual curation and human-in-loop annotation strengthen reliability and prevent declining confidence weights as datasets grow and evolve.
How does real-time tagging support personalization and analytics?
Streaming enrichment and real-time tagging capture user intent modeling signals as interactions occur. Query expansion and facet filtering improve metadata-driven analytics and search relevance.
Freshness timestamps and version control maintain data accuracy. Feature store metadata supports recommendation systems, funnel attribution, and cohort analysis context, leading to measurable improvements in personalization layers and decision-making accuracy.
When Should You Invest in Enriching Metadata with Context?
Organizations should enrich metadata with context when accuracy, compliance, or AI reliability affects operations, revenue, or regulatory exposure. High-value scenarios include GDPR compliance, AI-driven recommendations, multi-document reasoning, and real-time Network Threat Detection.
Pipelines ingesting data from Snowflake, BigQuery, or Databricks benefit most. Contextual enrichment transforms raw metadata into actionable knowledge, improves discoverability, strengthens retrieval, and reduces hallucination. For RAG systems or advanced AI workflows, structured enrichment is foundational.
Start Building Smarter Retrieval Systems Today
References
- https://www.sei.cmu.edu/blog/dealing-with-noisy-behavioral-analytics-in-detection-engineering/
- https://nvlpubs.nist.gov/nistpubs/specialpublications/nist.sp.800-150.pdf
