
Centralized log management takes logs from everywhere, servers, apps, your network, cloud platforms, and puts them all in one searchable spot. Think of it as swapping a wall of disconnected monitors for a single, coherent dashboard.
If you’ve wasted an afternoon SSH-ing into servers to hunt down a fault, you already know the problem this fixes. It turns messy, overwhelming data into structured, useful information. This shift doesn’t just save time; it changes how your team handles efficiency and security from the ground up. To see the real impact, keep reading.
Why the Benefits of Centralized Log Management Matter
- It creates a unified, searchable record of all activity for faster security investigations and threat detection.
- It drastically cuts troubleshooting time by giving engineers one place to search across the entire environment.
- It automates and standardizes log retention, making compliance audits straightforward and defensible.
The Night That Changed Our Perspective

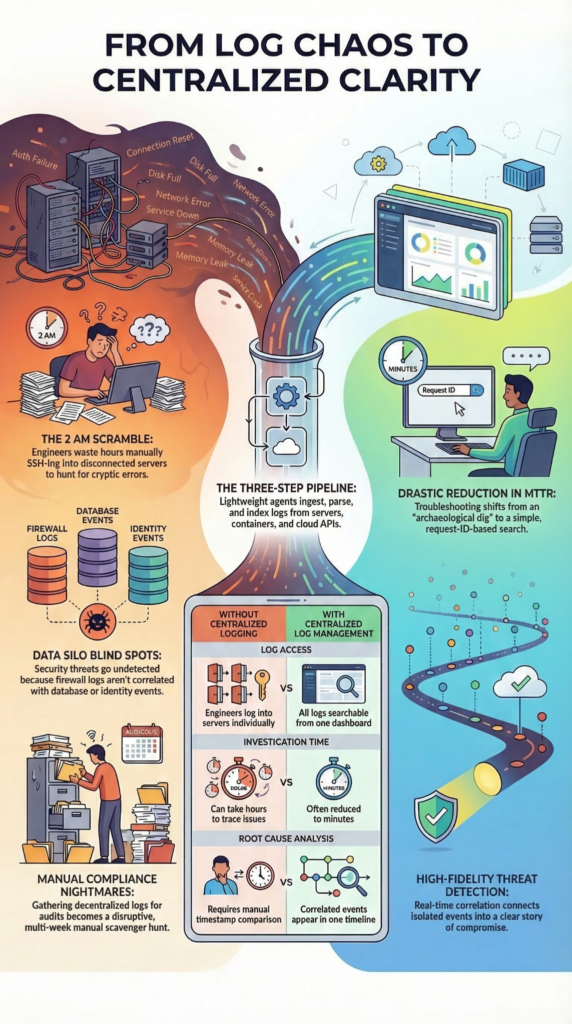
I remember the exact moment the value of centralized logging clicked for me. It was 2 AM, and our payment service was throwing cryptic errors. My team was scattered across terminal windows, each logged into a different microservice, shouting timestamps across a Zoom call.
We were detectives without a case file, piecing together a narrative from fragments. That incident, which took over an hour to resolve, would have been a ten-minute query in a proper system. That’s the visceral benefit: it turns a reactive scramble into a calm, methodical investigation.
The mechanics are simple on paper. You deploy lightweight agents or configure your services to forward their log streams, from Apache web servers, Kubernetes pods, cloud APIs, network firewalls, to a central platform.
This pipeline ingests terabytes of data, parses it into structured fields, and indexes it. Suddenly, that opaque wall of text becomes something you can ask questions of. You’re not just collecting data, you’re building a coherent timeline of your digital estate.
- Unified ingestion from servers, containers, and cloud services.
- Real-time parsing and indexing of log streams.
- A single query language to interrogate petabytes of history.
The alternative is what we all know too well. Logs languish on local disks, rotated out and lost forever right when you need them. Compliance reports become a quarterly nightmare of manual aggregation. A security alert on a firewall can’t be correlated with a simultaneous database query from the same IP address because the data sits in two different silos. Centralization breaks down those walls.
The First and Most Critical Benefit: A Defender’s Advantage
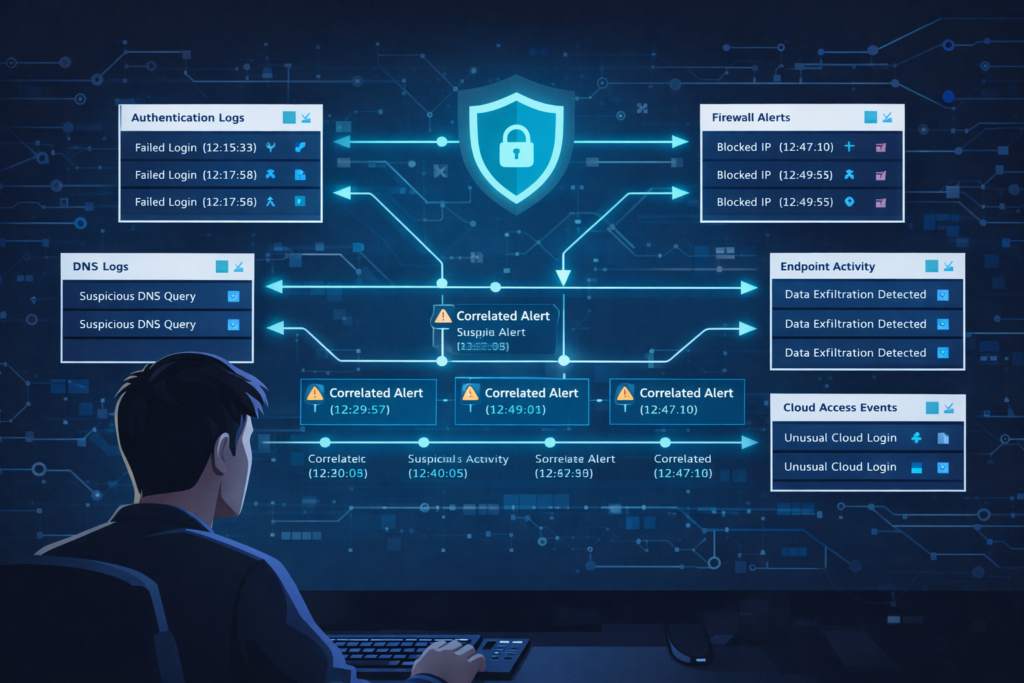
From a security perspective, and this is where we focus our own efforts, centralized logging is non-negotiable. You cannot defend what you cannot see, and you cannot see what is not correlated. For Network Threat Detection, this is our foundation.
We’re not just looking at flows; we’re integrating those flows with authentication logs, DNS queries, and endpoint process events collected from essential log sources for NTD across the environment. An attack is rarely a single event.
It’s a sequence, a failed login here, a lateral movement attempt there, an unusual outbound connection moments later. Isolated, each event might look benign. Together, in a centralized timeline, they tell a story of compromise.
“The lack of sufficient log data hinders incident response efforts by reducing visibility and delaying incident identification… CentralizedlogmanagementCentralized log managementCentralizedlogmanagement facilitates log usage and analysis for many purposes, including identifying and investigating cybersecurity incidents, finding operational issues, and ensuring that records are stored for the required period of time.” — NIST Cybersecurity Log Management Planning Guide
This unified visibility is what enables true threat detection. Automated rules can scan this consolidated feed, correlating events across different log sources in real-time. A rule might look for a pattern where a user account authenticates from a new country and, within minutes, attempts to access a sensitive S3 bucket.
That’s a high-fidelity alert. Without centralization, the auth log is in Active Directory, the cloud trail log is in AWS, and no one connects the dots until the data is exfiltrated. The mean time to detection (MTTD) plummets when your data is already together.
- Correlate events across network, identity, and cloud boundaries.
- Detect multi-stage attacks that leave traces in different systems.
- Hunt for threats using historical data across months, not days.
From Hours to Minutes: The Troubleshooting Revolution
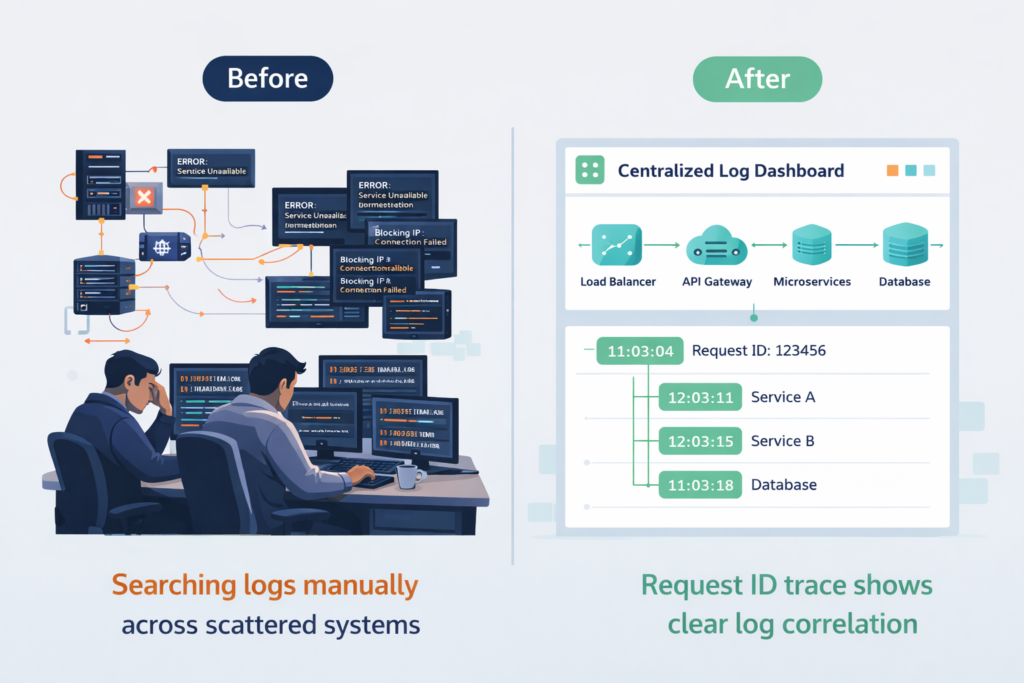
For engineers drowning in distributed systems, centralized logging is a lifeline. The mean time to resolution (MTTR) isn’t just a metric, it’s a measure of user pain and operational load. When an alert fires, the first question is “what changed?”. Finding the answer used to be an archaeological dig. Now, it’s a search.
You can trace a user’s request ID from the load balancer, through the API gateway, into three different microservices, and finally to a database timeout, often with insights revealed through metadata analysis tools comparison approaches used in modern observability workflows. The entire journey is reconstructed in one console.
“As mentioned earlier, logs can be generated from various sources, these create data silos if stored and handled independently. It is important that all these data sources are aggregated into a single logging platform. This approach simplifies searchability, correlation, and analysis by providing a unified view of system activity. Centralized logging reduces the complexity of troubleshooting in distributed environments, where logs are often spread across multiple locations.” — Logs-The First Pillar of Observability
This capability transforms post-mortems and proactive maintenance. You can search for error frequencies over time, spotting a gradual degradation before it becomes an outage.
You can compare logs between environments, understanding why something works in staging but fails in production. The cognitive load of managing infrastructure drops significantly because the data you need to understand its behavior is finally accessible. It turns debugging from an art into more of a science.
| Scenario | Without Centralized Logging | With Centralized Log Management |
| Log Access | Engineers log into multiple servers individually | All logs searchable from one dashboard |
| Root Cause Analysis | Requires manual timestamp comparison | Correlated events appear in a single timeline |
| Incident Investigation Time | Can take hours to trace issues | Often reduced to minutes |
| Visibility Across Systems | Logs remain isolated in silos | Full visibility across services and infrastructure |
| Debugging Distributed Systems | Difficult to trace requests between services | Request IDs can be tracked across systems |
Making Peace with the Auditors
Credits: Cloud Security Alliance (CSA)
Compliance often feels like a tax on engineering. GDPR, PCI DSS, HIPAA, they all demand that you know who did what, where, and when. They demand proof, and they demand it for specific retention periods.
Trying to satisfy this with decentralized logs is a recipe for anxiety. Centralized log management brings order to this chaos.
You establish one policy: all security-relevant events are sent here, indexed, and stored for 365 days, while teams remain aware of privacy implications metadata collection when handling user activity and system telemetry. Access is controlled and audited. The platform becomes your single source of truth.
When an audit letter arrives, you don’t panic. You run a report. You can demonstrate user access reviews, show immutable records of configuration changes, and prove data access patterns.
The platform handles the retention and the integrity, often with write-once-read-many (WORM) storage features to prevent tampering. What was a multi-week scavenger hunt becomes a series of verified, automated reports. It turns compliance from a disruptive project into a maintained state of being.
Scaling Without Stumbling
A common fear is that a central system will become a bottleneck or a money pit. This is where modern architecture shines. The leading platforms are built on distributed systems like Elasticsearch or OpenSearch, designed to scale horizontally. You add nodes as your data grows.
They use compression and tiered storage, keeping hot data on fast disks for recent searches and moving colder data to cheaper object storage. This controls costs. The idea isn’t to collect everything blindly, but to collect strategically.
You filter out debug noise in development, you sample extremely verbose health-check logs, and you keep the critical security and error events. This thoughtful ingestion is key to a sustainable system.
The Voice of Experience: What Practitioners Actually Use
You don’t have to take my word for it. Spend time in communities like r/devops and you’ll see the same patterns. For lightweight, cost-sensitive container logging, Grafana Loki comes up constantly, it’s built for that use case.
For a robust, all-in-one system that handles parsing, dashboards, and alerting out of the box, Graylog is a frequent favorite, especially for infrastructure logs. The open-source ELK/OpenSearch stack remains a powerhouse for teams willing to manage more of the underlying complexity for maximum flexibility.
The choice isn’t about a “best” tool, but the best fit for your volume, team skills, and budget. The unanimous thread in these discussions is the relief teams feel after centralizing. The chaos of “log soup” is replaced with a manageable, queryable system.
- Grafana Loki for Kubernetes and high-volume, low-cost needs.
- Graylog for out-of-the-box parsing and a gentle learning curve.
- OpenSearch/ELK for maximum power and customization.
Navigating the Pitfalls
It’s not all automatic wins. The biggest mistake is the “collect everything and pray” approach. Ingesting every debug log and verbose trace will bloat your storage and drown your team in noise, leading to alert fatigue. The security team starts ignoring alerts because 99% are false positives. The solution is a deliberate log governance policy.
Define what must be collected for security and compliance, what is useful for operations, and what can be sampled or dropped. Start with a minimum viable collection and expand deliberately.
Another challenge is access control; you must segment data so the development team can’t see production PII, while the SOC can see the security events they need. Done poorly, centralization creates a new risk. Done well, it enforces consistent governance.
FAQ
How does centralized log management improve threat detection?
The benefits of centralized log management appear clearly when security teams investigate suspicious activity. Centralized security logging collects logs from multiple sources and provides centralized log visibility across systems. Analysts can perform security log correlation and structured log analysis for incident response. This approach supports log management for threat detection and improves log monitoring for security teams, allowing them to identify unusual behavior earlier and respond faster.
Why is log aggregation important for security monitoring?
Log aggregation benefits security monitoring by bringing network log aggregation, endpoint log management, and server log centralization into one location. This unified approach strengthens security event log management and supports log management for cybersecurity. Security teams can run cross system log analysis to detect patterns and anomalies that remain hidden when logs stay scattered across systems.
How does centralized logging support compliance and audits?
Log management for compliance becomes easier when organizations implement centralized audit logging and structured centralized log reporting. Centralized logging for compliance audits provides consistent records of system activity. Proper log retention management also ensures that logs remain available for investigation and regulatory review. These practices support log management for regulatory compliance and strengthen enterprise security logging across the organization.
Can centralized logging improve troubleshooting and system reliability?
Centralized logging significantly improves log management for system troubleshooting because teams can review centralized infrastructure logs and application log centralization in one place. Engineers can analyze infrastructure monitoring logs using log data analysis tools to identify the root cause of failures. Centralized observability logs also improve log visibility across systems, which helps IT teams diagnose issues faster and maintain system reliability.
How does centralized logging help teams manage cloud and distributed systems?
Distributed system log management becomes easier when organizations implement unified log management and multi source log collection. Centralized logging for cloud environments, centralized logging for microservices, and container log management combine logs into a single system. This approach supports scalable log management and improves log analytics for cybersecurity. Security telemetry centralization also helps teams monitor large cloud and hybrid infrastructures more effectively.
The Log Management Mandate
Centralized log management gives teams a unified view of system behavior, making security monitoring, troubleshooting, and compliance far more effective. Instead of scattered logs, organizations gain a clear operational record for faster, evidence-based decisions.
Ready to consolidate your chaos? Start by identifying your five most critical log sources, or join here to explore centralized visibility.
References
- https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-92r1.ipd.pdf
- https://www.allmultidisciplinaryjournal.com/uploads/archives/20250327162407_F-21-118.1.pdf
