
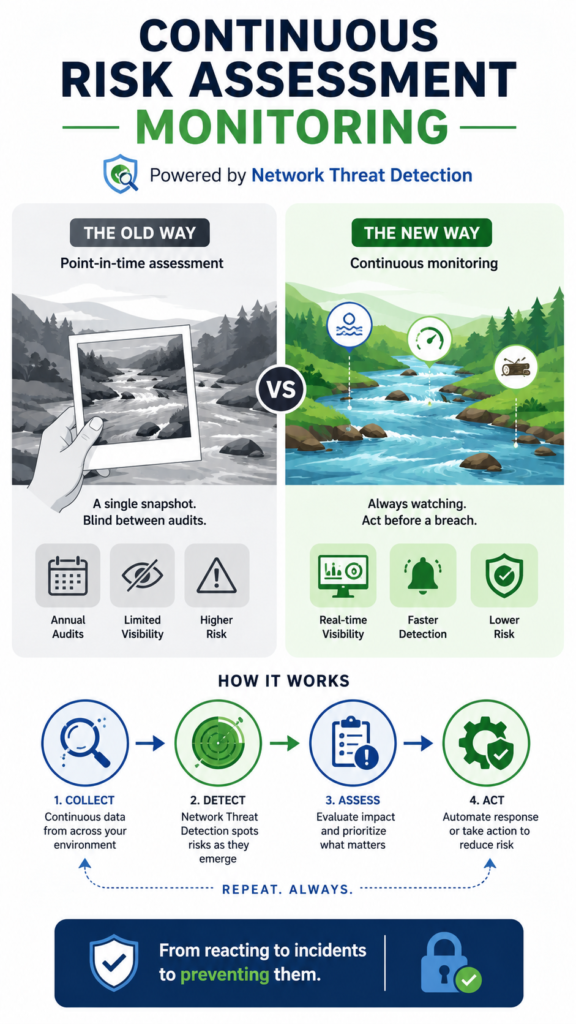
You can’t manage what you don’t measure, and you certainly can’t secure it. That’s the brutal truth of cybersecurity. Static, point-in-time risk assessments are like taking a single snapshot of a rushing river and calling it safe for crossing. Continuous risk assessment monitoring is the alternative.
It’s the process of constantly watching that river’s depth, current, and debris. This isn’t about more reports, it’s about gaining a living, breathing understanding of your threat landscape so you can act before a breach happens. Combined with modern Network Threat Detection capabilities, organizations can identify emerging risks faster. Keep reading.
Quick Wins from Continuous Monitoring
Before we explore the process, here are three reasons organizations are moving toward continuous risk assessment monitoring:
- Continuous monitoring turns security from a periodic audit into an always-on, operational reality.
- It relies on specific, automated tools like Network Threat Detection to see risks as they emerge.
- The ultimate goal is proactive action, shifting your team from reacting to incidents to preventing them.
Why Does a One-Time Checkup Fail Modern Security?

Think about the last major security audit your organization went through. There was probably a flurry of activity, a final report packed with findings, and a list of recommendations. That report was accurate for that single moment in time.
The moment a new employee onboarded with excessive permissions, or a critical server patch was missed, or a shadow IT application was spun up in the cloud, that report became a historical document, not a security guide.
The digital environment is fluid. Assets change, configurations drift, and new vulnerabilities are published daily. Relying on an annual assessment is a bit like checking your home’s locks once a year while leaving the windows open every night.
You get a false sense of security. The gap between assessments is where breaches live. Continuous monitoring closes that gap by providing a constant stream of data about your actual security state, not the idealized one from your last audit.
You need a system that automatically tracks:
- New assets appearing on your network
- Changes to critical system configurations
- Emerging software vulnerabilities
- Unusual user or network behavior patterns
What Does Continuous Risk Monitoring Actually Look Like in Practice?
Credits: Pathlock
It starts with visibility. You can’t assess the risk of something you can’t see. In the past, this meant manual inventory spreadsheets and network scans run every quarter. Now, a foundational step involves identifying network assets through deploying sensors and agents that provide a real-time, unified view.
From our own experience building security programs, the shift from manual to automated asset discovery was the first, non-negotiable step. You’d be shocked how many devices and services exist without the IT team’s knowledge.
The core of continuous monitoring is the telemetry, the data flowing in from your endpoints, cloud workloads, identity systems, and, most critically, your network. Network Threat Detection provides a foundational layer here. It sees the raw traffic, the conversations between machines, the attempts to move laterally.
It operates on the principle that while an endpoint can be compromised and lie, the network traffic tells the objective truth. We’ve seen it catch crypto-mining malware on a developer’s laptop that every endpoint tool missed, simply by spotting the anomalous outbound connections to a mining pool.
How Do You Move From Just Watching to Actually Managing Risk?
Observation without action is just expensive entertainment. The real value of a continuous model is its ability to trigger workflows. A high-fidelity alert about a critical, exploitable vulnerability on an internet-facing server should automatically generate a ticket in the IT service management system, assigned to the correct team with all the context attached.
A detection of ransomware-like file encryption behavior on a finance department PC should immediately initiate an automated isolation of that endpoint.
This is where you move from risk assessment to risk management. The process creates a closed loop:
- Identify a new risk (e.g., an unpatched server).
- Map it to a risk analysis matrix to determine severity based on context and potential impact (e.g., it holds customer data).
- Prioritize it against other risks (e.g., it’s more urgent than an internal test server).
- Treat the risk (e.g., deploy the patch).
- Verify the treatment worked (e.g., confirm the patch is installed).
The table below contrasts the old, static cycle with modern network security risk analysis continuous cycles:
| Phase | Traditional (Periodic) Cycle | Continuous Monitoring Cycle |
| Identify | Manual discovery every 6-12 months. | Automated, real-time discovery of assets & threats. |
| Analyze | Isolated analysis of found items. | Contextual analysis tied to business impact. |
| Prioritize | Subjective, based on report findings. | Dynamic, based on real-time threat intelligence. |
| Treat | Long remediation projects post-audit. | Integrated, automated workflows trigger immediate action. |
| Verify | Checked at next audit cycle. | Continuously verified; alerts re-open if issue recurs. |
The rhythm changes completely. Your security team stops being historians, documenting past breaches, and starts being forecasters, preventing future ones. They spend less time chasing false positives and more time validating true threats, because the system has already done the initial heavy lifting of correlation and prioritization.
Can a Smaller Team Really Implement This Without Burning Out?
This is the common fear. Continuous sounds like 24/7, which sounds like exhaustion. But paradoxically, a well-tuned continuous monitoring program reduces alert fatigue and manual toil. The key is in the tuning and the integration.
You start small. Don’t try to monitor every possible thing on day one. Pick a critical area, say, your public-facing web servers or your crown jewel data repository. Deploy your visibility tools there first.
Focus on high-fidelity alerts. It’s better to have one alert that you always act on than a hundred you routinely ignore. Use the automation not just for detection, but for enrichment and triage.
Let the system add context: “This vulnerable service is on Server A, which is owned by the Marketing team, and it holds no sensitive data.” That context alone can turn a high-priority panic into a medium-priority task.
The tools do the endless watching. Your team does the intelligent decision-making. It’s a force multiplier. From a practical standpoint, you’ll need a platform that pulls together vulnerability data, network telemetry, endpoint alerts, and cloud configuration states.
The implementation crawl-walk-run looks like this:
- Crawl: Gain complete asset visibility. Deploy a Network Threat Detection capability to see all east-west and north-south traffic.
- Walk: Integrate vulnerability scans and correlate findings with your asset inventory and network context to prioritize.
- Run: Automate response playbooks for top-priority risks, like auto-isolating hosts or creating urgent patching tickets.
Where Do Most Organizations Stumble When They Try to Start?
They buy a tool and call it a day. Technology is an enabler, not a strategy. The first stumble is treating continuous monitoring as a software purchase instead of a process change. You need to define what “risk” means to your business. Is it data exfiltration? Service disruption? Compliance fines? Your monitoring priorities flow from that definition.
“Asset discovery is a fundamental but inherently flawed capability in cybersecurity, as current methodologies frequently confuse preliminary discovery observations with definitive asset inventories, thereby obscuring uncertainty, restricting auditability, and eroding trust in security-critical decision-making.” – MDPI
The second stumble is siloed data. The network team has its logs, the cloud team has its own dashboard, and the security team has a vulnerability scanner. None of them talk. Continuous assessment requires breaking down these silos.
A risk on the network (like a command-and-control call) plus a risk on an endpoint (like a suspicious process) together equal a high-confidence incident. Alone, they might be dismissed as noise.
Finally, there’s the culture of blame. If the monitoring system surfaces a misconfigured server, the response cannot be to punish the server owner. It must be to fix the server and understand how the misconfiguration happened.
How Does This Fit With Compliance Frameworks Like ISO or NIST?
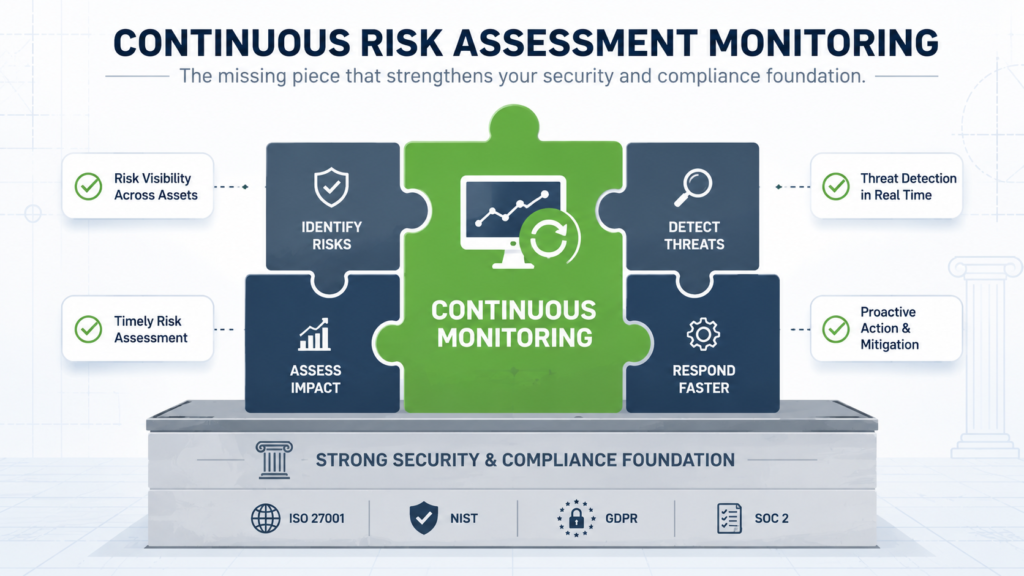
Beautifully, and it often simplifies the burden. Frameworks like NIST SP 800-53 and ISO 27001 have long required continuous monitoring components. Control families like “Security Assessment and Authorization” (CA) and “Monitoring” (AU) in NIST are built for it. Traditionally, companies satisfied these with manual, sample-based checks before an audit.
A mature continuous monitoring program doesn’t just check boxes, it proves control effectiveness over time. Instead of showing an auditor a spreadsheet saying you have a vulnerability management policy, you can show a live dashboard demonstrating that 99% of critical vulnerabilities are patched within your 7-day SLA.
“This thesis develops a comprehensive vulnerability management framework for IT service organizations to protect sensitive data and harden their security posture. The research emphasizes the importance of early vulnerability detection using static and dynamic testing, maintaining a detailed asset inventory, and conducting regular risk assessments.” – Aaltodoc
It turns compliance from a narrative exercise into a demonstrable fact. The evidence is generated automatically, as a byproduct of doing security well, not as a frantic scramble during audit season.
FAQ
Does continuous risk monitoring replace traditional penetration tests and audits?
No, it complements them. Think of penetration tests as deep, expert-led offensives that find complex flaws. Continuous monitoring is the persistent, automated defense that finds the common, everyday risks and ensures old flaws don’t creep back in. You need both for a complete picture.
What’s the biggest technical hurdle to getting started?
Usually, it’s data integration. Getting your various tools, vulnerability scanners, cloud security posture managers, endpoint protection, and network sensors, to feed data into a central correlation engine is the technical challenge. Start by connecting just two critical sources, like network and endpoint data, to prove value before expanding.
How do you measure the success of a continuous monitoring program?
Don’t measure by the number of alerts. Measure by metrics that matter to the business: Mean Time to Detect (MTTD) and Mean Time to Respond (MTTR) should go down. The percentage of critical assets covered by monitoring should go up. The number of audit findings related to unknown assets or unpatched systems should drop to zero.
Is this only for large enterprises with big security budgets?
The principle is for everyone, but the tools scale. A small business can start with a core set of integrated cloud-native tools that provide visibility into their key assets (like their website and customer database) without a massive investment. The mindset of constant vigilance is free; you apply the tools you can afford to your most critical risks first.
The Shift to Continuous Vigilance
Continuous risk assessment isn’t a feature, it’s a fundamental rethinking of security as a dynamic, living system. Instead of relying on rigid, once-a-year audits, it transforms your defense into a resilient posture capable of adapting to shifting digital perimeters and evolving threats in real time.
Stop navigating today’s threats with yesterday’s information. Start by securing your most critical system, exposing blind spots, and gaining true visibility. Watch Your River: Start Monitoring Now
References
- https://www.mdpi.com/2624-800X/6/2/67
- https://aaltodoc.aalto.fi/items/88d7df85-8fd4-4918-bbcc-f863eaafb10f
