
Automating data enrichment processes helps reduce API costs, improve data accuracy, and prevent stale records with scalable enrichment pipelines.
Automating data enrichment processes helps businesses turn incomplete records into accurate, usable data without wasting engineering resources or API budgets. Modern enrichment pipelines improve lead scoring, fraud detection, customer intelligence, and workflow automation, but poorly designed systems can quickly create stale records, duplicate data, and rising infrastructure costs. Building a resilient enrichment architecture is essential if you want scalable automation that stays reliable over time.
Automated Data Enrichment Quick Wins
Modern enrichment pipelines succeed when they balance speed, accuracy, and cost efficiency across every stage of the workflow.
- Cache Aggressively or Pay Repeatedly: A Redis layer preventing duplicate API calls is non-negotiable for cost control.
- Embrace the Fallback: No single data source is perfect. Robust pipelines use waterfall logic across multiple vendors.
- Validate Early, Validate Often: Garbage in gives you automated garbage out. Standardization before enrichment is critical.
Understanding Automated Data Enrichment and Its Business Impact
We often start with a bare list of leads from a form, or IPs from firewall logs. Automated data enrichment is the process that builds out these sparse records. It matches them against sources to add missing details: company revenue, location, or tech stack.
In B2B, data decays fast, roughly 30% each year. Contacts move, companies get bought, tech stacks change. Manual updates can’t keep pace. We automate these updates so security tools and CRMs always use current data. The impact is straightforward: sharper threat models, better lead scoring, and fewer false positives in our risk analysis. It turns a raw log into a real asset.
The Process Behind an Automated Data Enrichment Pipeline
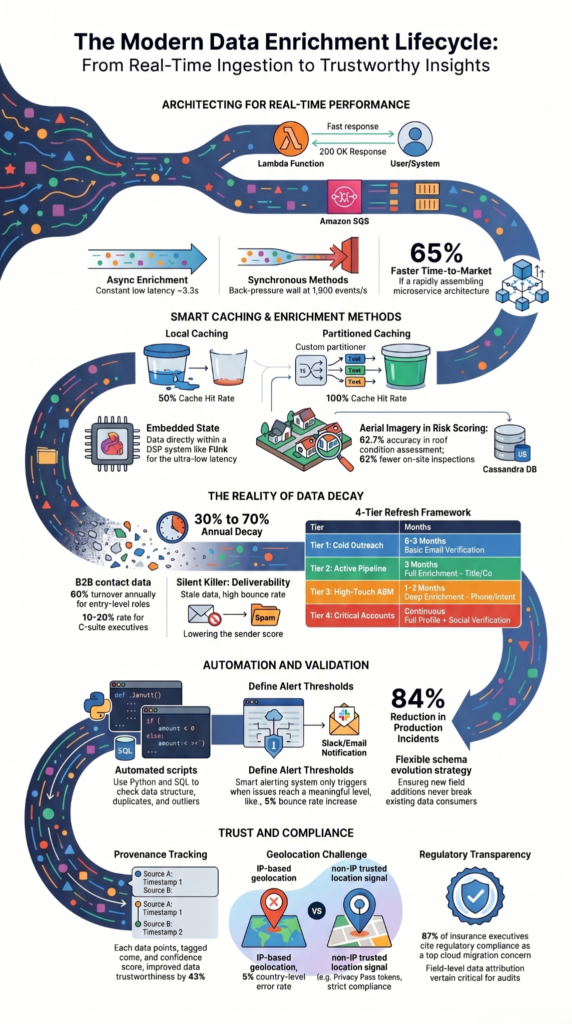
An enrichment pipeline is like an assembly line for data. Our work typically uses an ETL (Extract, Transform, Load) flow with enrichment as a critical transform stage.
It starts with a trigger for a new entry in a log or a database. We ingest the raw data, then clean it. This step is crucial; we standardize phone numbers and validate domains to avoid wasting resources on bad inputs.
Next, our engine queries the sources: a primary API, a backup, or our own databases. We’ve seen sources contradict each other, so we built rules to resolve conflicts, often prioritizing the provider with better accuracy for that specific data point. The enriched record is then delivered, often in under a second, to our analytics or security systems, where enrichment query performance directly affects how quickly downstream analysis can react to new activity.
Data Enrichment Types That Deliver the Highest ROI
Enrichment value depends on your goal. We see three types giving the most return.
Firmographic data is a B2B staple. A domain yields industry, employee count, and tech stack. It drives account-based marketing, but the data goes stale quickly companies change.
Demographic enrichment targets consumers, using an email to infer age or income. It’s powerful for personalization but must navigate privacy laws like GDPR carefully.
For us, geographic enrichment is often the first critical step. An IP address gives us country, city, and timezone. We use this to build threat models, distinguishing normal international traffic from suspicious logins. We account for VPNs, because services like Cloudflare can be accurate, but not foolproof.
| Enrichment Type | Data Added | Primary Use Case | Key Risk |
| Firmographic | Revenue, Employee Count, Tech Stack | ABM, Lead Scoring | Stale, outdated company info |
| Demographic | Income, Household Size, Age Bracket | Consumer Targeting | Privacy compliance exposure |
| Geographic | Country, City, ISP, Timezone | Fraud Prevention, Localization | IP rotation & VPN noise |
Common Reasons Automated Enrichment Pipelines Fail at Scale
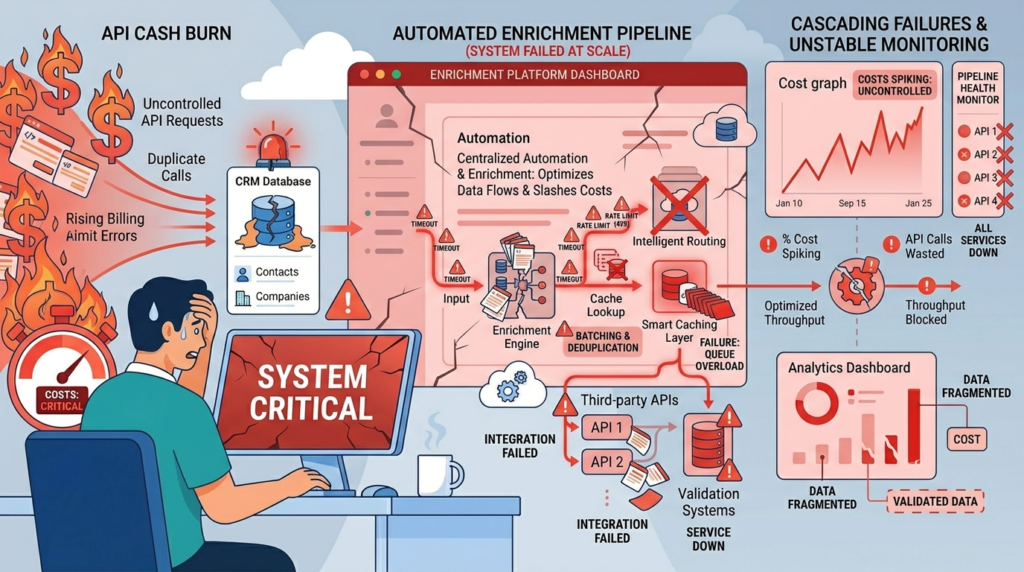
We see automated pipelines fail for a few common reasons. The first is simple: bad input creates bad output. Automating a process that takes messy data just corrupts records faster.
As noted by Ramp:
“In the age of artificial intelligence, the adage ‘garbage in, garbage out’ has never been more relevant.” –Ramp
Another frequent issue is schema drift. An API changes its response format without warning, and our rigid pipeline starts dropping fields or throwing errors. We’ve also dealt with recursive loops, where a bug causes the same record to be enriched endlessly, spiking our API costs overnight.
Using AI agents for web scraping introduces a state problem. The logic holding the enrichment context together often falls apart after a few thousand rows, making the output fragmented. Teams trying to automate threat detection workflows run into similar scaling issues when enrichment logic loses consistency across high-volume events. These aren’t rare bugs; they’re what happens when you treat enrichment as a simple call instead of a fault-tolerant system.
Preventing API Cost Explosions and Vendor Lock-In in Data Enrichment Systems
The fear of runaway costs or vendor lock-in is real. Our first defense is a caching layer. Before any external call, we check a fast store like Redis. If we enriched that domain recently, we use the cached data. This one step can slash API costs dramatically.
We also design for multiple sources. Our logic queries the primary, most accurate vendor first. If there’s no match, it automatically tries a secondary, more affordable one. The final fallback is our own internal database of past results. This saves money and improves our overall match rate.
Finally, we never let enrichment block a user. For a new sign-up, we don’t wait for five APIs. We acknowledge it immediately and use a queue like AWS SQS to process the enrichment in the background. This keeps our systems responsive and resilient.
The Role of LLMs and AI Agents in Modern Data Enrichment
Source: IBM Technology
The game is changing. Beyond static databases, teams are now using LLMs like Gemini for semantic enrichment. An AI agent can scrape a website, read its blog, and infer company culture or project focus. This is contextual intelligence you can’t get from a standard API.
In a recent analysis by arXiv
“Despite their increasing adoption, a fundamental challenge is to ensure the reliability of their generated responses. A particular issue is that LLMs are prone to hallucinations where they confidently generate false or misleading information.” –arXiv
We see this in lean growth stacks where premium data is too expensive. But it brings new risks. Hallucination is one; the LLM might confidently add wrong details. More practically, these agentic workflows often break at scale. Managing context across thousands of scrapes is a distributed systems challenge. The promise is real, but building it requires careful engineering to avoid a pipeline that’s clever but ultimately brittle.
Managing Data Quality, Compliance, and Observability in Enrichment Pipelines
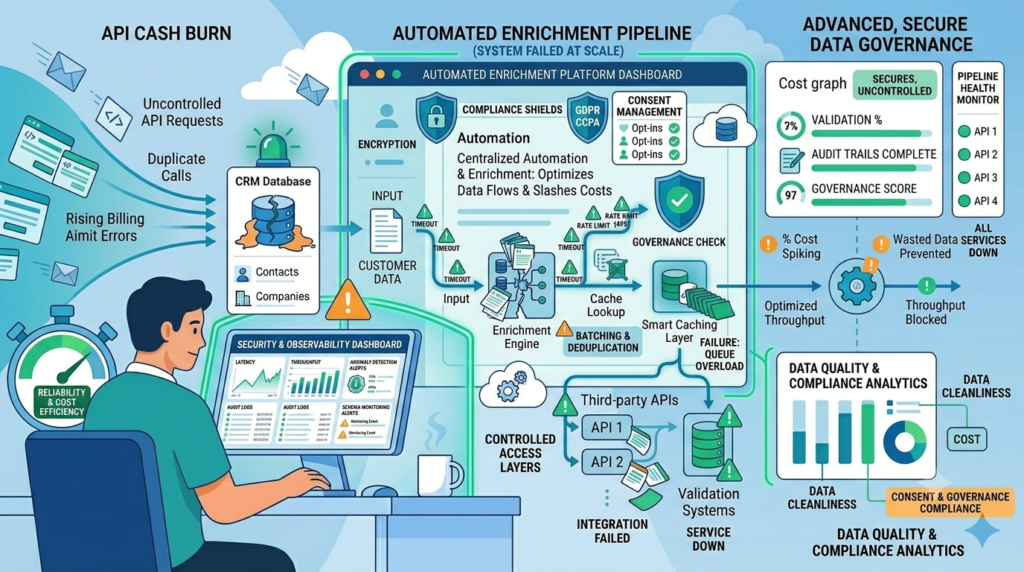
You can’t manage what you don’t measure. That old saying is at the heart of making enrichment work. We need observability tools that watch our data as closely as we watch our servers.
Specialized platforms can spot problems: a sudden drop in records from a source, or a spike in null values for a critical field. Schema monitoring tools alert us when an API changes its structure. For the pipelines themselves, we use testing libraries to run validation rules in production, making sure the data quality we designed for is what we actually get.
Compliance is tricky with automation. It helps enforce rules but can also spread mistakes faster. Our pipelines must respect “Do Not Sell” flags and have a way to delete personal data when asked. Strong data integrity practices become essential here, especially when records are refreshed repeatedly across multiple enrichment sources. For business data, accuracy fades over time. We set up automated refresh policies, where active records get re-enriched every 6 to 12 months. It’s a basic rule for keeping things trustworthy.
FAQs
How does automated data enrichment improve incomplete customer records?
Automated data enrichment improves incomplete customer records by combining internal business data with trusted third-party data sources. The process supports customer data enrichment, contact enrichment, and profile enrichment by filling missing fields with verified information. Businesses also use data validation, data normalization, and duplicate detection to improve long-term data accuracy and consistency.
What makes an automated data enrichment workflow scalable and reliable?
A scalable automated data enrichment workflow relies on strong data integration, workflow automation, and clearly defined enrichment logic. Businesses often combine batch enrichment with real-time enrichment to process large datasets efficiently. Reliable workflows also include audit trails, automated record updates, and data quality automation to reduce processing errors and maintain accurate records.
Why is data standardization important in lead enrichment automation?
Data standardization is essential in lead enrichment automation because inconsistent formats create errors during data matching and data merging. Standardized records improve identity resolution across CRM systems, marketing databases, and customer data platforms. Clean and consistent data also strengthens sales intelligence, marketing automation, and overall data quality improvement initiatives.
How do enrichment APIs support real-time data processing automation?
An enrichment API supports real-time data processing automation by connecting systems through automated API integration and continuous data syncing. Businesses use enrichment APIs to automate data extraction, account enrichment, and prospect data enrichment without manual intervention. Many organizations also combine API-based workflows with ETL automation to improve scalable enrichment and database enrichment performance.
What role does AI data enrichment play in modern data pipelines?
AI data enrichment improves modern data pipelines by using machine learning enrichment, semantic enrichment, and contextual enrichment to analyze complex datasets. These systems help businesses process behavioral data, demographic data, and technographic data more accurately. Combined with data governance and master data management, AI-driven enrichment improves data completeness and supports better operational decisions.
Building Enrichment Pipelines That Hold Up Over Time
If your enrichment pipeline keeps breaking every time a vendor changes an API or data starts conflicting, you’re not saving time, you’re creating more cleanup work later. Teams usually focus too much on processing speed and ignore resilience until failures pile up. That’s the problem.
A stronger setup keeps things stable even when providers fail or costs spike unexpectedly. Network Threat Detection can help teams build workflows that handle outages, retries, and messy data without turning operations into constant maintenance. It’s a practical step if you want enrichment systems that last longer and require less engineering effort.
References
- https://arxiv.org/abs/2510.06265
- https://ramp.com/leading-indicators/trends-in-data-enrichment-vendors-q1-2025
