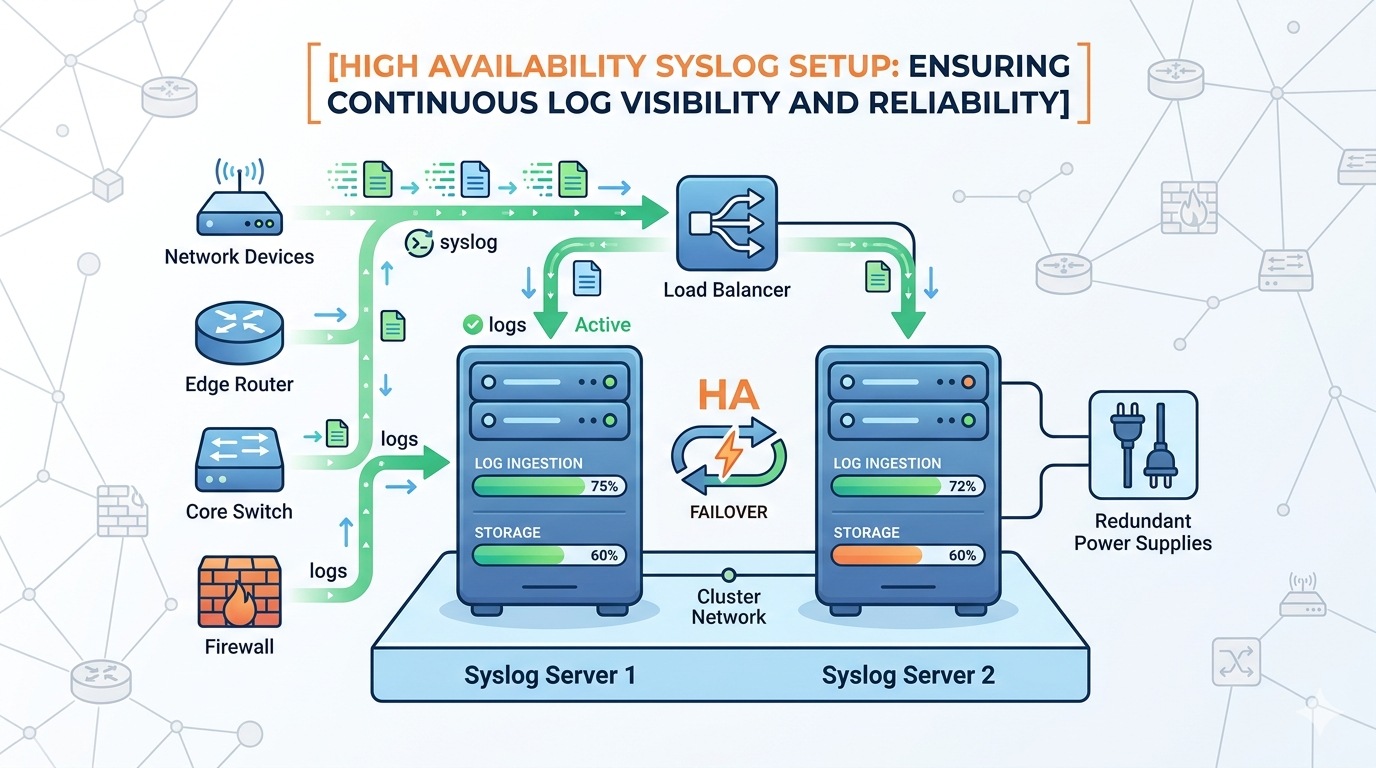
A high availability syslog setup is critical for maintaining continuous visibility across your infrastructure. In our experience, even short logging interruptions can create blind spots that attackers exploit. Many teams focus on collecting logs but overlook system resilience. When syslog systems fail, detection pipelines collapse silently.
This article explains how to design a reliable, fault-tolerant syslog architecture that ensures logs are always available when needed. Keep reading to learn how to build a resilient logging system that supports security operations effectively.
Key Insights for High Availability Syslog Setup
High availability syslog setup is about eliminating single points of failure while ensuring consistent log delivery.
- Design for redundancy at every layer
- Use load balancing to distribute log traffic
- Ensure failover mechanisms are automatic
Why High Availability Matters in Network Threat Detection

We emphasize Network Threat Detection because logging availability directly impacts detection capability.
- Prevents blind spots during outages
- Ensures continuous threat visibility
- Supports real-time monitoring systems
- Strengthens incident response readiness
From our experience, even a few minutes of log loss can delay detection significantly. High availability ensures that detection systems always have the data they need to function effectively.
“High availability is a characteristic of a system, which aims to ensure an agreed level of operational performance, usually uptime, for a higher than normal period.” – Wikipedia
Core Components of a High Availability Syslog Setup
Building a reliable syslog system requires combining multiple architectural components, starting with understanding syslog protocol and configuration to ensure every node is properly aligned.
- Redundant syslog servers (active-active or active-passive)
- Load balancers to distribute incoming logs
- Failover mechanisms for automatic recovery
- Log buffering to prevent data loss
- Centralized storage systems for consistency
We have found that active-active configurations provide better performance, while active-passive setups are simpler to manage.
Example High Availability Architecture Table
Credits: Learning Software
| Component | Role | Benefit |
| Load Balancer | Distributes syslog traffic | Prevents overload |
| Primary Server | Main log processing node | Handles normal operations |
| Secondary Server | Backup node | Ensures failover support |
| Log Buffer/Queue | Temporary storage | Prevents data loss |
| Central Storage | Long-term log retention | Enables analysis and compliance |
This architecture ensures both resilience and scalability.
Challenges in High Availability Syslog Setup
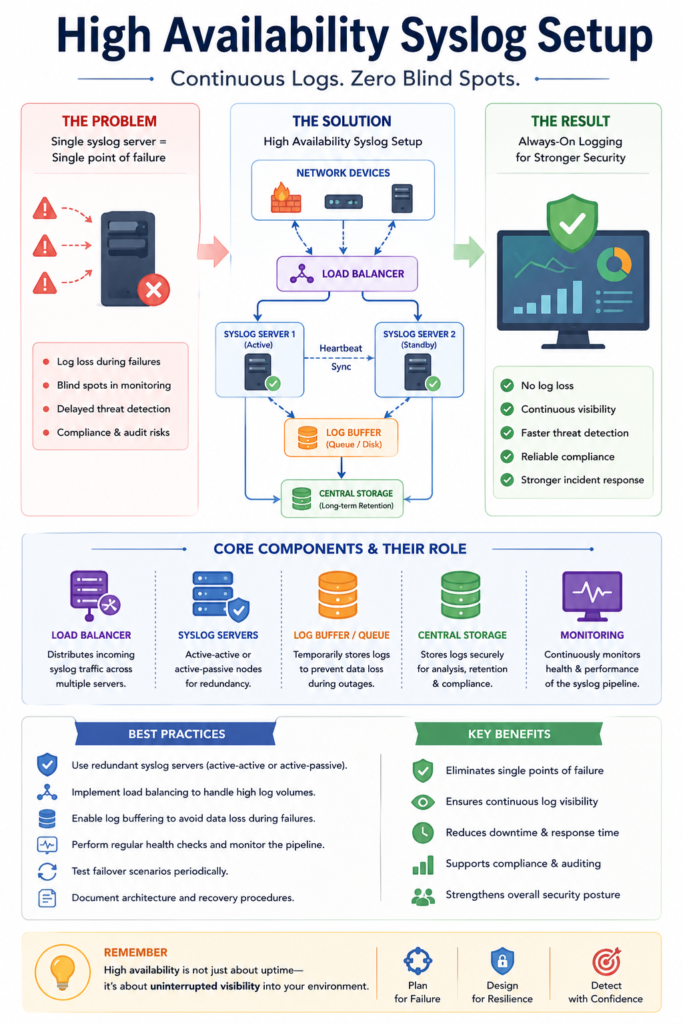
Implementing high availability introduces complexity that must be managed carefully, particularly when parsing unstructured syslog data across multiple synchronized nodes.
- Increased infrastructure costs
- Configuration complexity
- Synchronization between nodes
- Risk of duplicated logs
- Monitoring multiple components
From firsthand experience, synchronization issues between redundant servers are often overlooked, leading to inconsistencies in log data.
“Reliability engineering involves designing systems that continue to operate properly in the presence of failures.” – Wikipedia
Best Practices for High Availability Syslog Setup
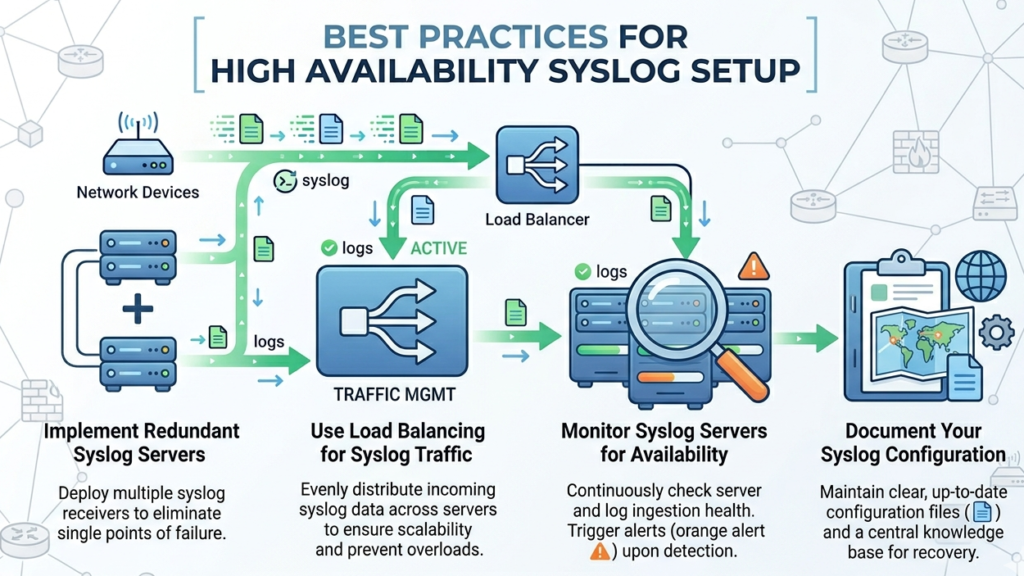
To maintain reliability, systems must be designed with both resilience and observability in mind. Beyond redundancy, filtering syslog messages ensures that your high availability cluster isn’t overwhelmed by low-value data.
- Implement health checks for all syslog nodes
- Use reliable transport protocols (e.g., TCP, TLS)
- Regularly test failover scenarios
- Monitor log ingestion and processing rates
- Document architecture and recovery procedures
We have learned that failover testing is often skipped, yet it is crucial to ensure systems behave correctly during real failures.
FAQ
What is a high availability syslog setup?
A high availability syslog setup ensures that log collection and processing continue without interruption, even if one or more components fail. It uses redundancy, failover, and load balancing to maintain continuous operation.
Why is redundancy important in syslog systems?
Redundancy eliminates single points of failure. If one syslog server goes down, another can take over immediately, ensuring no logs are lost and monitoring continues uninterrupted.
How does load balancing improve syslog availability?
Load balancing distributes incoming log traffic across multiple servers, preventing overload and ensuring consistent performance even during high traffic periods.
Can high availability prevent data loss completely?
While it significantly reduces the risk, it cannot guarantee zero data loss. However, combining buffering, redundancy, and failover mechanisms minimizes the impact of failures.
Building a Reliable High Availability Syslog Setup
Mastering high availability transforms syslog from a simple utility into a resilient security pillar. To proactively defend your network, explore Network Threat Detection. Their platform empowers SOCs with real-time threat modeling, automated risk analysis, and visual attack path simulations.
By utilizing frameworks like MITRE ATT&CK and CVE mapping, teams can streamline vulnerability management, expose critical blind spots, and significantly reduce incident response times before attackers can strike.
References
- https://en.wikipedia.org/wiki/High_availability
- https://en.wikipedia.org/wiki/Reliability_engineering
