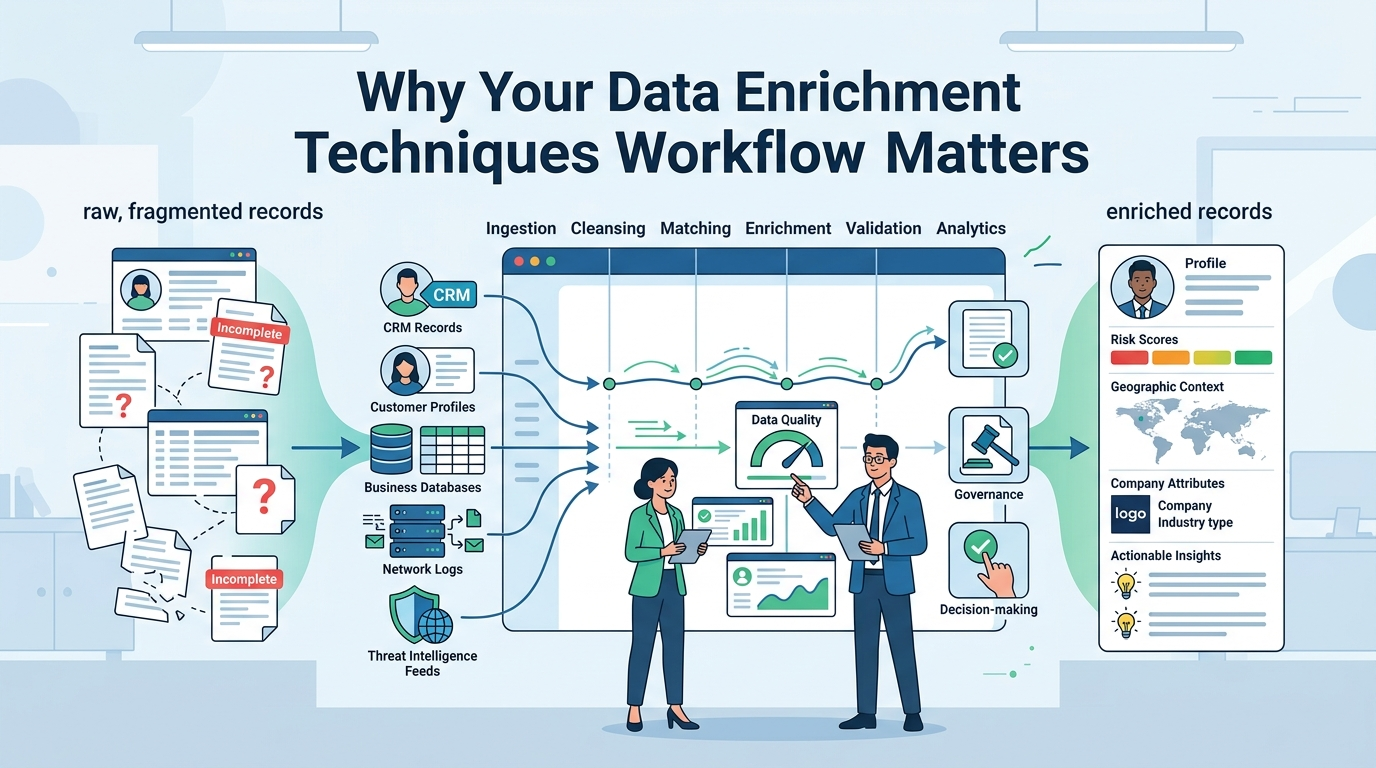
Data Enrichment Techniques Workflow is the process of taking raw data and adding meaningful context so teams can make better decisions. We see this regularly in our work with network threat detection. An IP address alone tells very little, but adding reputation, ownership, or threat intelligence data turns it into something useful.
Organizations rely on enrichment to improve accuracy, reduce guesswork, and get more value from existing data. As data volumes grow, having a structured workflow becomes increasingly important. Keep reading to see how an effective enrichment workflow supports quality, scale, and long-term reliability.
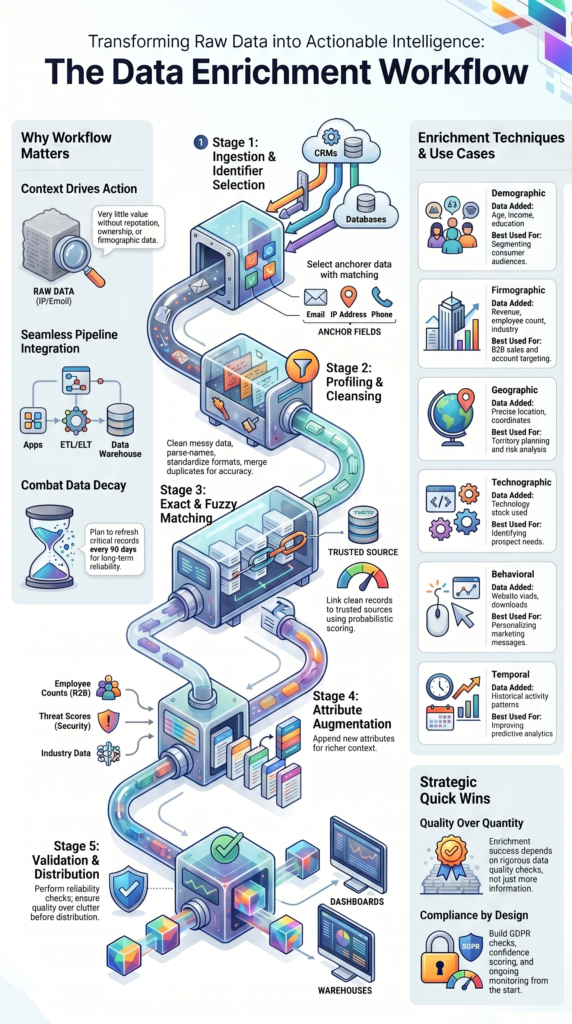
Data Enrichment Workflow: Quick Wins to Remember
A successful data enrichment techniques workflow depends on more than adding new data. The most reliable workflows combine quality controls, validation, automation, governance, and ongoing maintenance.
- Enrichment succeeds on data quality and checks, not just collecting more information.
- Plan to refresh your most important records every 90 days to fight data decay.
- Build in GDPR checks, confidence scoring, and ongoing monitoring from the start.
What Is a Data Enrichment Workflow and Why Does It Matter?
Think of a data enrichment workflow as a system. It takes your basic records and systematically adds valuable details from outside sources. A CRM contact gets a company’s industry and estimated revenue. A customer profile might gain age range or past purchase behavior.
In our projects, we treat this as foundational. For threat detection, enriching a network log with geolocation and threat intelligence turns a raw event into a prioritized alert. The principle is universal: context drives action.
Most enterprise data pipelines now bake enrichment right into their ETL or ELT processes. Data flows continuously from apps to warehouses to analytics platforms, getting smarter along the way. Teams use it for sharper sales targeting, deeper customer personalization, and more accurate machine learning models.
Before getting into the technical architecture, it helps to break down the core stages every workflow shares.
Core Workflow Stages
- Bring the data in.
- Profile and clean it.
- Match records to trusted sources.
- Augment with new attributes.
- Validate the results.
- Send the good data where it needs to go.
How Does the End-to-End Data Enrichment Process Work?
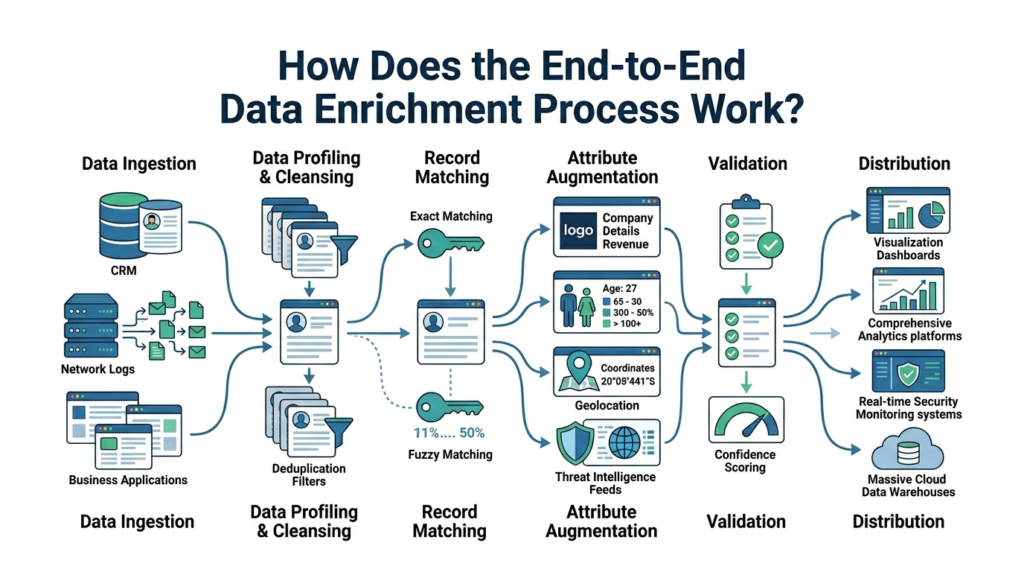
The process follows a logical path. You find your records, clean them up, match them to something reliable, add new info, check your work, and finally ship it out.
We typically structure it as a 5-stage workflow.
Stage 1: Data Ingestion and Identifier Selection
You start by pulling in records from wherever they live, your CRM, transaction databases, internal apps, or even real-time streams. The first job is picking your anchor fields. These are the identifiers you’ll use to find matching data elsewhere.
Common anchors are:
- Email addresses
- Company names
- Phone numbers
- IP addresses
- Internal customer IDs
Get this step wrong, and everything downstream gets harder.
Stage , Data Profiling, Parsing, and Cleansing
You can’t enrich messy data. This stage is all about cleanup. We parse full names into first and last. We format dates and phone numbers into standard layouts. We find and merge duplicates. We toss out entries that are clearly invalid.
If your anchors are full of errors, your matches will be too. This step is non-negotiable.
Stage 3: Exact and Fuzzy Matching
Now you try to link your clean record to a trusted reference source. Sometimes you get a perfect match on an email. Often, you don’t. That’s where fuzzy matching comes in. It uses algorithms to handle typos, missing words, or different formats.
We use probabilistic scoring here. It gives each potential match a confidence score, which helps automate decisions later.
Stage 4: Attribute Augmentation
This is where you add the new data. For a business, you might append firmographics like employee count or industry codes. For a person, it could be demographics. In security, we’re adding things like threat reputation scores or associated malware families to an IP address.
The value of this process becomes much clearer when organizations understand the importance of security data enrichment context in transforming isolated indicators into actionable intelligence.
Stage 5: Validation and Distribution
Finally, you check the enriched record before it goes live. Does the source seem reliable? Does the new data make sense alongside the old? Then you push it out, to your data warehouse, your CRM, your security dashboard. According to groups like DAMA, these validation controls are what separate useful data from clutter.
Which Data Enrichment Techniques Deliver the Most Value?
Different techniques solve different problems. Picking the right one depends on what you’re trying to learn or do.
| Technique | Data Added | Best Used For |
| Demographic Enrichment | Age, income, education level | Segmenting consumer audiences |
| Firmographic Enrichment | Revenue, employee count, industry codes | B2B sales and account targeting |
| Geographic Enrichment | Precise location, coordinates | Planning sales territories or analyzing risk |
| Technographic Enrichment | Technology stack used | Sales teams identifying prospect needs |
| Behavioral Enrichment | Website visits, content downloads | Personalizing marketing messages |
| Temporal Enrichment | Historical activity patterns | Improving predictive analytics |
In our B2B work, firmographic enrichment is a powerhouse. Knowing a company’s size and industry helps our sales team prioritize accounts. For our marketing, demographic and behavioral data creates much sharper customer segments.
For network security, geographic and temporal enrichment are critical. Seeing that a login attempt comes from a country the user never visits, or happens at a strange hour, adds immediate context to the threat.
How Can You Build a Cost-Efficient Multi-Provider Enrichment Pipeline?
Credits: Sunil Kumar
Costs can spiral if every data lookup hits a premium API. We’ve felt that “credit anxiety” ourselves. A smarter approach uses a waterfall strategy across multiple providers.
The idea is simple: you rank your data sources by cost and completeness. You always query the cheapest, most general source first. If it comes back with a complete result, you stop. If fields are missing, you route the record to the next provider up the chain.
Our Waterfall Routing Strategy
Our typical pipeline might query a broad commercial database first. If the company revenue field is empty, it automatically tries a more specialized B2B provider. Only the toughest records escalate to the most expensive, high-precision sources. Orchestration tools handle this logic, checking response completeness at each step.
Verification Before Record Updates
Before any new data hits our production systems, it runs through checks:
- We review the confidence score from the provider.
- We might spot-check contact info against other sources.
- We ensure it meets our GDPR and consent requirements.
- We confirm it fits the expected data schema.
Reducing Provider Dependency
Relying on a single vendor is risky. Their API goes down, your enrichment stops. Their pricing changes, your budget blows up. Using multiple sources isn’t just about cost; it’s about resilience and better coverage. We’ve seen fill rates improve by 20% or more just by adding a second or third provider into the mix.
Batch vs Real-Time Enrichment: Which Architecture Should You Choose?
Your choice here defines what you can do with the data. Batch processing is for scale; real-time is for speed.
| Factor | Batch Enrichment | Real-Time Enrichment |
| Speed | Updates take hours or days. | Results come in milliseconds. |
| Cost | Generally lower per record. | Higher due to infrastructure needs. |
| Scale | Great for huge, historical datasets. | Needs robust systems to handle load. |
| Best For | Updating a whole CRM, monthly reporting. | Live personalization, instant threat blocking. |
We use batch enrichment all the time for large-scale CRM updates and syncing our data warehouse. It’s efficient and manageable.
As highlighted by Quix Blog
“If you have limited compute resources and your use case isn’t particularly time sensitive, you could run the enrichment in batches. Once a night when other computing demands are lower, for example. But, thanks to tools like Quix, you can run the enrichment in real-time as the data comes in from sources…” – Quix Blog
But in our security tools, real-time enrichment is non-negotiable. When our system sees a suspicious login, it can’t wait. It needs to enrich that IP address with threat intelligence now to decide whether to block the session. That requires a tight setup with event streaming, fast APIs, and automated validation running in the background.
How Do You Prevent Data Quality Failures and “Garbage In, Garbage Out” Outcomes?
Automation can’t save bad data. We’ve learned that the hard way. The quality of what goes in dictates the value of what comes out.
Deduplication Controls
Our first line of defense is merging duplicates and resolving identities. We run algorithms that spot similar records, maybe “Jon Doe” and “Jonathan Doe” at the same company, and link them before enrichment begins. Letting duplicates wastes money and creates confusion.
Confidence Thresholds
Every piece of appended data gets a confidence score from our system. We set rules: anything below an 85% confidence doesn’t auto-update a live record. It gets flagged for a team member to review. This stops low-quality guesses from polluting our databases.
Compliance Validation
This is especially crucial in the EU or with personal data. Our workflow checks for proper consent flags, ensures we’re not retaining data longer than allowed, and masks sensitive fields where needed. Good governance isn’t just about risk; it makes the entire dataset more trustworthy for everyone using it.
How Can Organizations Handle Schema Drift and Silent API Changes?
This is a sneaky problem. An external data provider updates their API response, adding a new field or changing a format, and your pipeline breaks. Or worse, it starts loading junk data silently.
We defend against it in a few ways.
Detecting Unexpected Fields
We use strict JSON Schema validation. Our system knows exactly which fields to expect from each provider. If a new, unmapped field appears, the record fails validation automatically and goes to an exception queue instead of crashing the whole process.
This becomes even more important when enrichment pipelines support broader data enrichment for contextual analysis initiatives that depend on consistent and trustworthy data structures.
Validation Gateways
We built a dedicated validation checkpoint, a gateway, that all enriched data must pass through. It’s the last stop before production. It checks schema, data types, and value ranges.
Exception Handling Workflows
Records that fail don’t just disappear. They go into a dashboard for our data engineers to inspect. Often, a schema drift is the cause. This gives us a chance to update our field mappings in a controlled way, without causing downtime.
Why Is Data Vault Architecture Important for Enrichment Resilience?
Many teams realize they need this only after something goes wrong. Data Vault is a method that stores raw, unaltered source data permanently alongside your processed data.
Raw Data Preservation
We store the original API response from every enrichment call, exactly as we received it. This feels like extra work upfront, but the benefits are huge. We can always go back and verify what the source sent us.
In larger environments, this approach complements practices commonly used in asset management database integration CMDB strategies, where preserving source records supports governance, traceability, and operational accuracy.
Replay and Recovery
If we improve our matching logic next month, we can re-run it over the past year’s stored raw data. We don’t have to pay for the API calls again or worry about the source data having changed. This is a lifesaver for debugging and improving processes.
Audit and Lineage Benefits
When an auditor or an internal team asks, “Why does this record have this attribute?” We have a complete answer. We can show the raw source, the processing logic, and the exact timing. It builds tremendous trust in the data’s integrity.
When Should Human-in-the-Loop Validation Be Added?
Machines are fast, but they’re not always right. Knowing when to involve a person is key.
Low-Confidence Matches
Our rule is simple: if the system isn’t sure, a human should check. Records with confidence scores in our “review” range get routed to a simple queue. A team member quickly confirms or rejects the match. This stops ambiguous data from slipping through.
Research from Carnegie Mellon University (CROW / SEI)
“Human-in-the-loop (HITL) machine learning is an effective approach to automate data enrichment tasks in a SOC [Security Operations Center] while still relying on human expertise to validate outputs and reduce false positives. HITL should be added when the cost of an incorrect automated decision is high, such as when escalating an alert to a full incident.” – Carnegie Mellon University (CROW/SEI)
Regulatory Workflows
For data governed by strict regulations, we sometimes mandate a human checkpoint regardless of confidence. It creates a clear audit trail that a person approved the data use.
Escalation Paths
We also flag records for human review when there’s a conflict between sources, or when a record is linked to a very high-value account. The potential impact of an error is too high to leave to automation alone.
What Are the Most Common Data Enrichment Workflow Mistakes?
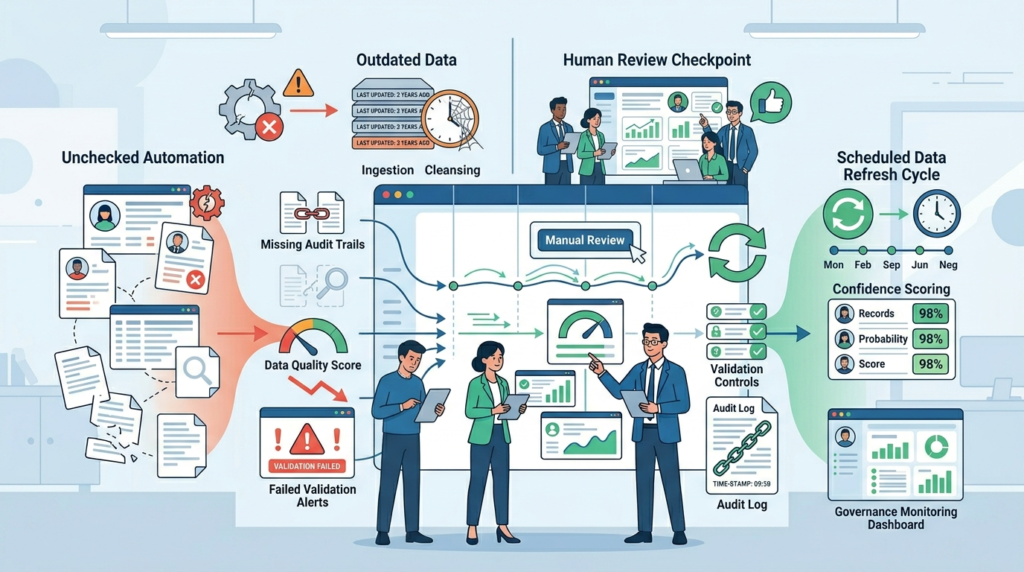
Over the years, we’ve seen a few mistakes show up again and again. We’ve also learned some of these lessons firsthand while building threat models, running risk analysis, and improving our own enrichment processes.
Over-Reliance on Automation
Automation saves time, but it should not run without oversight. A workflow can look fine on the surface while small data issues spread across thousands of records. We’ve found that regular reviews, spot checks, and manual sampling help catch problems early. Teams that rely only on automation often discover errors much later, when they are harder to fix.
Ignoring Refresh Cycles
Even high-quality data loses value over time. People change roles, organizations merge, and technical assets such as domains and IP addresses can change ownership. In our experience, scheduled re-enrichment is essential. We refresh priority accounts on a regular basis because stale data weakens security analysis and reduces confidence in decision-making.
Missing Audit Trails
Another common issue is poor visibility into where enriched data came from. When a record cannot be traced back to its source or processing date, investigations become slow and frustrating. That’s why we log each stage of the workflow, from ingestion and matching to enrichment and validation. Clear audit trails make troubleshooting easier and support compliance requirements.
FAQ
How do I choose the right data enrichment providers?
The right data enrichment providers depend on your business goals, budget, and data requirements. Some companies focus on customer data enrichment and CRM data enrichment, while others need B2B data enrichment or lead data enrichment.
Compare providers based on data accuracy, coverage, update frequency, compliance standards, and integration capabilities. A reliable data enrichment service should improve data quality and fit smoothly into your existing processes.
What should I look for in a data enrichment pipeline architecture?
A strong data enrichment pipeline architecture should support accuracy, scalability, and reliability. It should include data matching enrichment, entity resolution enrichment, data validation enrichment, and data deduplication enrichment.
The system should also support both batch data enrichment and real time data enrichment. These capabilities help maintain data quality while allowing the pipeline to process growing volumes of information efficiently.
Which data enrichment techniques provide the most useful customer insights?
The most useful data enrichment techniques depend on the type of insight you need. Demographic data enrichment helps identify customer characteristics such as age and income.
Behavioral data enrichment shows how customers interact with products, services, or content. Psychographic data enrichment provides information about interests and preferences. Combining these methods with transactional data enrichment creates a more complete customer profile for analysis.
How can organizations improve data enrichment security and compliance?
Organizations can improve data enrichment security by establishing clear policies for collecting, storing, and using data. Data privacy enrichment practices help protect sensitive information, while GDPR data enrichment requirements support regulatory compliance.
Regular audits, access controls, and data governance processes reduce risk and improve accountability. Strong data compliance enrichment practices also help maintain trust in enriched datasets across the organization.
What role does a data enrichment API play in automation?
A data enrichment API allows systems to exchange and update information automatically. Organizations often use enrichment data APIs within ETL data enrichment, ELT data enrichment, and broader data pipeline enrichment workflows.
These APIs connect data enrichment software, data enrichment platforms, and internal systems. As a result, teams can automate updates, reduce manual work, and keep data current across sales, marketing, analytics, and operational processes.
Build a Data Enrichment Process You Can Trust
Even the best enrichment tools can create problems when data isn’t checked, tracked, or refreshed over time. That’s why scalable operations depend on validation, clear data lineage, and regular re-enrichment. The goal isn’t collecting more data, it’s making sure the information you rely on stays accurate when decisions matter.
If you’re looking to strengthen data-driven security operations, explore how Network Threat Detection helps teams uncover risks faster through threat modeling, automated analysis, and actionable intelligence.
References
- https://quix.io/docs/blog/2024/06/03/data-enrichment-with-quix-and-redis.html
- https://insights.sei.cmu.edu/blog/human-in-the-loop-machine-learning-for-security-applications/
